request와 json 패키지를 사용해서 JSON 데이터를 파싱할 때, 각 키의 데이터를 수정하려면 아래처럼 dictionary 형태로 변환시켜 value를 수정한다.
data = {"key1":"value1"}
data["key1"] = "value2"
전체 데이터를 스캔하여 특정 값을 가진 키를 찾으려고 한다.
아래 코드로 (for, if로) 전체를 확인하면서 원하는 값을 가진 키를 찾았다.
data = {
"key1":"value1",
"key2":"value2",
"key3":"value3",
"key4":"value4",
"key5":"value5",
}
for key in data:
if "value3" == data[key]:
print(key)
break
간단한 데이터라면 위 방식으로도 충분히 찾을 수 있다. 하지만 데이터의 수가 매우 많거나 복잡할때도 같은 방식으로 값을 찾고 수정할 수 있을까?
아래처럼 사람의 정보를 가진 JSON 데이터에서 "-", "N/A", "" 의 값을 가진 키를 찾아서 제거하려고 하는데 각 자료형도 다르고 형태도 일정하지 않다. 사람 수도 매우 많다고 가정하겠다.
{
"person_1":{
"name": {"first":"David", "middle":"", "last":"Smith"},
"age":12,
"address":"-",
"education":{"highschool":"N/A","college":"-"},
"hobbies":["running", "swimming", "-"],
},
"person_2":{
"name": {"first":"Mason", "middle":"henry", "last":"Thomas"},
"age":21,
"address":"-",
"education":{"highschool":"N/A", "college":"", "Universitry":"Stanford"},
"hobbies":["coding", "-", ""],
},
...
}
먼저 위 형태로 랜덤한 데이터가 원하는 만큼 생성되도록 함수를 만들었다.
아래 이미지를 보면 패턴이 있긴하지만 데이터가 잘 생성된거 같다.
def create_random_data(num:int) -> dict:
import random
data={}
random_string = lambda x: "".join([chr(random.randint(97, 122)) for tmp in range(x)])
for i in range(num):
key = f"person_{i+1}"
data[key] = {
"name":{"first":random_string(random.randint(0, 8)), "middle":random_string(random.randint(0, 8)), "last":random_string(random.randint(0, 8))},
"age":random.randint(10, 50),
"address":"-",
"education":{"highschool":random_string(random.randint(0, 8)), "college":"", "Universitry":random_string(random.randint(0, 8))},
"hobbies":["coding", "-", "", random_string(random.randint(0, 8))],
}
return data
print(create_random_data(5))
이제 파싱을 위한 함수를 만들어야하는데 위 데이터의 형태를 봤을 때 가장 문제가 될 것 같은 부분은 데이터의 깊이라고 생각했다.
데이터의 깊이에 상관없이 탐색할 수 있도록 재귀를 사용해 파싱 함수를 작성해보자.
def clean(data):
remove_keyword = ["N/A", "-", ""]
for key in list(data):
value = data[key]
if type(value) == dict:
clean(value)
if value == {}:
data.pop(key)
if type(value) == list:
for x in [keyword for keyword in remove_keyword if keyword in value]:
for _ in range(value.count(x)):
value.remove(x)
if type(value) == str:
if value in remove_keyword:
data.pop(key)
datas = create_random_data(5)
print(datas)
clean(datas.copy())
print(datas)
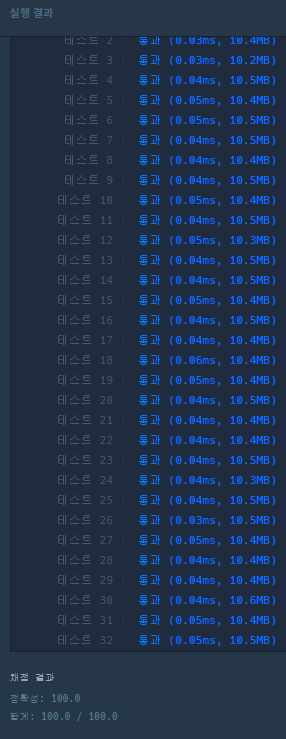
나름 잘 정리 됐다. 그런데 JSON 데이터 100만개를 처리하면 시간이 얼마나 걸릴지 궁금해져서 코드를 좀 더 수정해봤다.
https://hwan001.co.kr/178 글에 함수의 실행 시간을 측정하는 데코레이터가 있다.
재귀를 사용한 clean함수는 따로 작성해야겠지만 해당 코드를 사용해서 100만 건의 생성 시간과 정리 시간을 측정해보자.
def my_decorator(func):
def wrapped_func(*args):
import time
start_r = time.perf_counter()
start_p = time.process_time()
ret = func(*args)
end_r = time.perf_counter()
end_p = time.process_time()
elapsed_r = end_r - start_r
elapsed_p = end_p - start_p
print(f'{func.__name__} : {elapsed_r:.6f}sec (Perf_Counter) / {elapsed_p:.6f}sec (Process Time)')
return ret
return wrapped_func
@my_decorator
def create_random_data(num:int) -> dict:
import random
data={}
random_string = lambda x: "".join([chr(random.randint(97, 122)) for tmp in range(x)])
for i in range(num):
key = f"person_{i+1}"
data[key] = {
"name":{"first":random_string(random.randint(0, 8)), "middle":random_string(random.randint(0, 8)), "last":random_string(random.randint(0, 8))},
"age":random.randint(10, 50),
"address":"-",
"education":{"highschool":random_string(random.randint(0, 8)), "college":"", "Universitry":random_string(random.randint(0, 8))},
"hobbies":["coding", "-", "", random_string(random.randint(0, 8))],
}
return data
def clean(data):
remove_keyword = ["N/A", "", "-"]
for key in list(data):
value = data[key]
if type(value) == dict:
clean(value)
if value == {}:
data.pop(key)
if type(value) == list:
for x in [keyword for keyword in remove_keyword if keyword in value]:
for _ in range(value.count(x)):
value.remove(x)
if type(value) == str:
if value in remove_keyword:
data.pop(key)
datas = create_random_data(1000000)
print(len(datas), datas, "\n")
import time
start_r = time.perf_counter()
start_p = time.process_time()
clean(datas.copy())
end_r = time.perf_counter()
end_p = time.process_time()
elapsed_r = end_r - start_r
elapsed_p = end_p - start_p
print(f'{"clean"} : {elapsed_r:.6f}sec (Perf_Counter) / {elapsed_p:.6f}sec (Process Time)')
print(len(datas), datas)
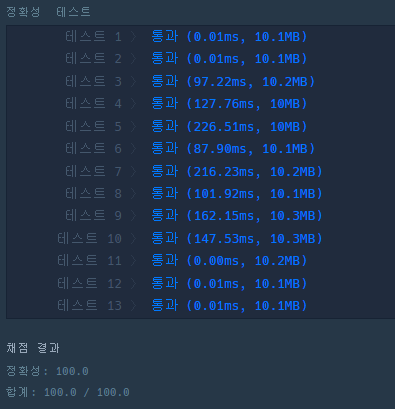
데이터가 길어서 다 나오지 않았기 때문에 키워드 개수와 데이터 일부를 찍어봤다.(키워드는 줄지 않음)
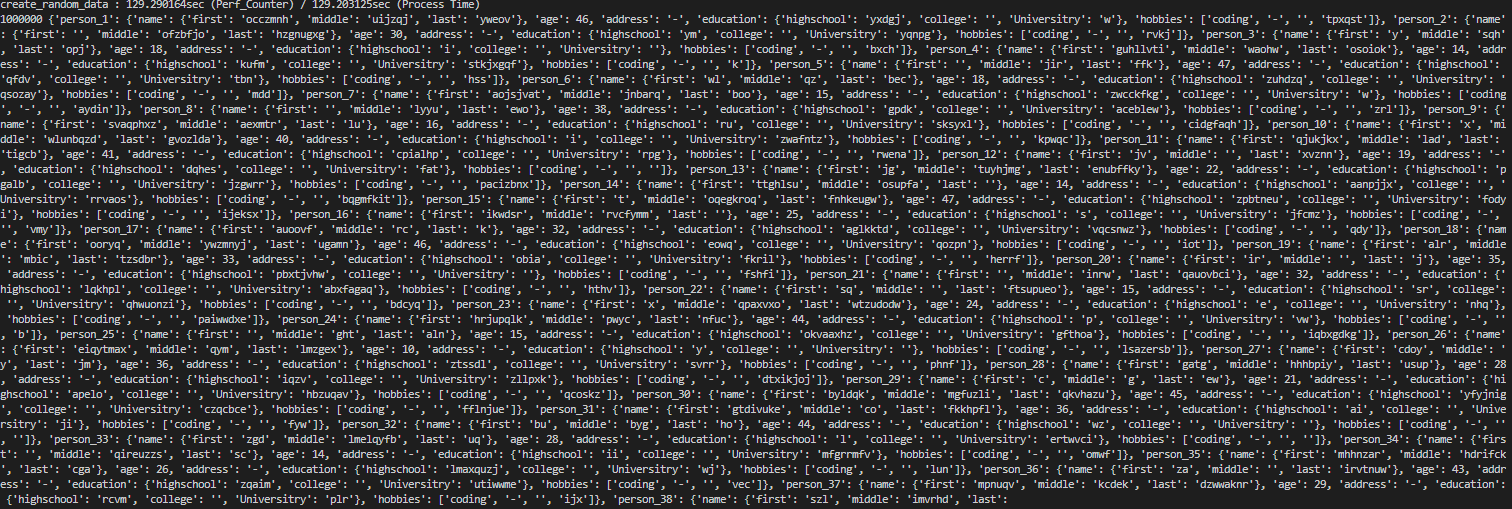
생성에 129. 3초, 정리에 13초가 걸렸다. 100만 개 정도부터는 확실히 탐색 속도가 느린게 느껴진다.
추가로 예시의 데이터에서는 깊이가 얕아서 재귀로도 문제없이 동작했지만 만약 깊이가 매우 깊다면 탐색 중에 메모리 에러가 발생된다.
재귀가 아닌 큐나 스택을 활용한 방식으로 변경해야 하고 실제로 사용하려면 좀 더 효율적인 알고리즘이 필요할 거 같다.
'코딩테스트 > 알고리즘' 카테고리의 다른 글
| [알고리즘] 순열과 조합 (0) | 2022.04.21 |
|---|---|
| [알고리즘] 다익스트라(Dijkstra) (0) | 2022.04.11 |
| [자료구조] 우선순위 큐 - 작성 중 (0) | 2022.04.11 |
| [알고리즘] 하노이의 탑 (0) | 2022.03.09 |
| [알고리즘] DFS/ BFS (0) | 2022.02.05 |
| [알고리즘] 달팽이 배열 채우기 (0) | 2021.11.06 |