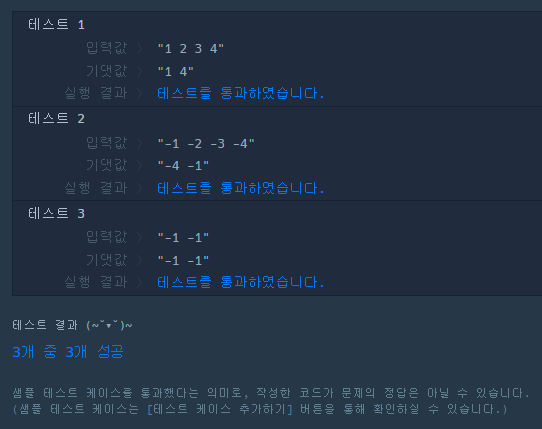
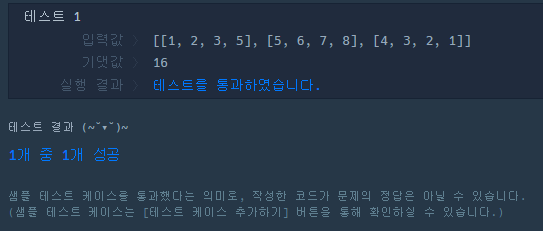
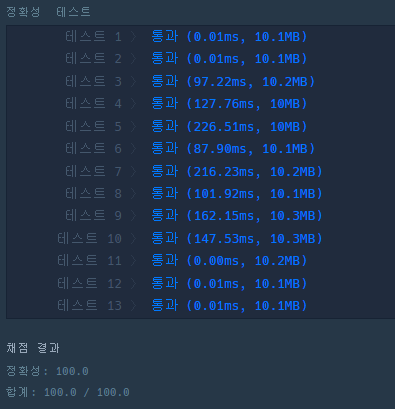
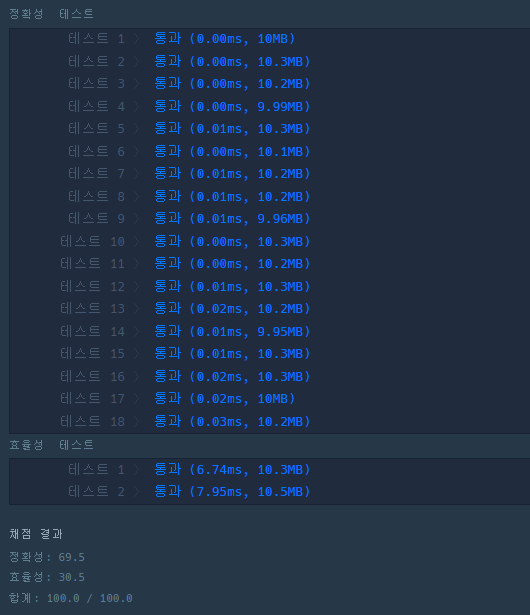
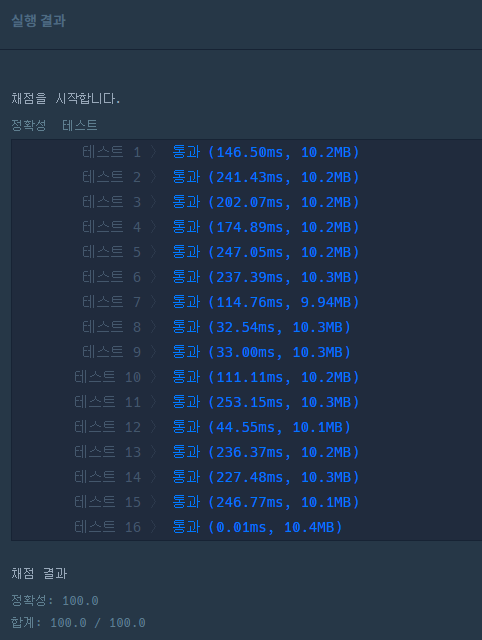
점화식 : 4개의 열(Column) 중 현재 열과 같은 열을 제외한 나머지 값 중 최대값을 현재값에 더한다.
for j in range(4):
land[i][j] += max([land[i-1][x] for x in list({0, 1, 2, 3} - {j})])
가장 큰 합들이 마지막 열에 반영되었기 때문에 가장 아래 열에서 최대값을 선택하면 된다.
3. 코드
def solution(land):
answer = 0
for i in range(1, len(land)):
for j in range(4):
land[i][j] += max([land[i-1][x] for x in list({0, 1, 2, 3} - {j})])
answer = max(land[len(land)-1])
return answer
가로를 x, 세로를 y라고 할 때, 주어진 brown과 yellow의 조합으로 xy와 x+y를 알 수 있다.
간단한 이차방정식을 만들고 이후는 완전탐색으로 값을 찾음
3. 코드
def solution(brown, yellow):
answer = []
x_y = int(brown / 2) + 2
xy = brown + yellow
for x in range(1, x_y):
for y in range(1, x_y):
if (x + y == x_y) and (x*y == xy):
if x >= y:
return [x, y]
return answer
def solution(citations):
citations = list(reversed(sorted(citations)))
len_citations = len(citations)
max_citations = max(citations)
h=0
for h in range(max_citations, 0, -1):
cnt = 0
for x in citations:
if x >= h:
cnt+=1
if cnt >= h:
break
return h
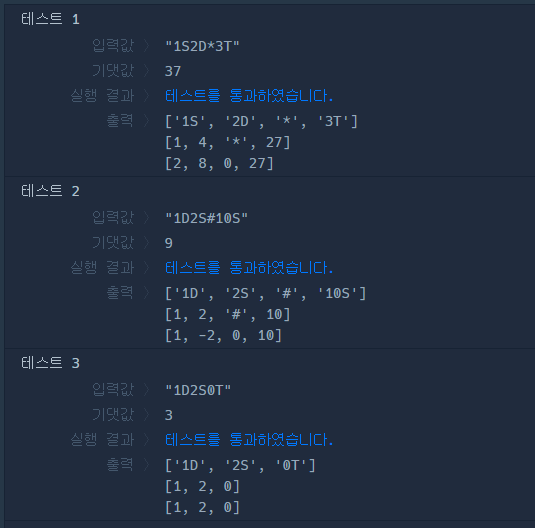
S, D, T, *, #을 공백을 포함하여 replace 후 공백으로 split 해주면 서로 분리됨(마지막 공백은 제거)
각 기호에 맞는 점수를 제곱해서 정수로 변경해줌
*은 현재와 이전 값에 *2 (해당 범위에 * 이나 다른 기호가 포함될 경우도 고려해서 미리 정수로 변경해줌)
#은 0으로 변경 후 현재 값에 -1
정수로 변환된 전체 리스트를 합쳐줌 -> 총점
3. 코드
def solution(s):
for str_tmp in ["S", "D", "T", "*", "#"]:
s = s.replace(str_tmp, str_tmp + " ")
res = [x for x in s.split(" ")][:-1]
for i in range(len(res)):
x = res[i]
if x == "*" or x == "#":
continue
if "S" in x:
res[i] = int(x.replace("S", ""))
if "D" in x:
res[i] = pow(int(x.replace("D", "")), 2)
if "T" in x:
res[i] = pow(int(x.replace("T", "")), 3)
for i in range(len(res)):
if res[i] == "*":
res[i] = 0
res[i-1] *= 2
if i-2 >= 0:
if res[i-2] != 0:
res[i-2] *= 2
else:
res[i-3] *= 2
if res[i] == "#":
res[i] = 0
res[i-1] *= -1
return sum(res)
최대 공약수 : 두 수 이상의 여러 수의 공약수 중 최대인 수 -> n과 m에 동시에 나눠지는 i 중 가장 큰 값
최소 공배수 : 두 수 이상의 여러 수의 공배수 중 최소인 수 -> n과 m을 곱한 값을 최대 공약수로 나눈 값 (유클리드 호제법)
더 쉬운 방법 : math 패키지 활용
import math
math.gcd(a, b)
math.lcm(a, b)
3. 코드
def solution(n, m):
answer = [1, 0]
# GCD
for i in range(1, m+1):
if n%i ==0 and m%i==0:
answer[0] = i
# LCM
answer[1] = n * m // answer[0]
return answer
-- 1. 모든 레코드 조회하기
SELECT * from animal_ins order by animal_id asc
-- 2. 역순 정렬하기
SELECT Name, datetime from animal_ins order by animal_id desc
-- 3. 아픈 동물 찾기
SELECT animal_id, name from animal_ins where intake_condition = "Sick" order by animal_id asc ;
-- 4. 어린 동물 찾기
SELECT animal_id, name from animal_ins where not intake_condition = "aged" order by animal_id ASC
-- 5. 동물의 아이디와 이름
SELECT animal_id, name from animal_ins order by animal_id asc
-- 6. 여러 기준으로 정렬하기
SELECT animal_id, name, datetime from animal_ins order by name asc, datetime desc
-- 7. 상위 n개 레코드
SELECT name from animal_ins order by datetime asc limit 1
-- 1. 최댓값 구하기
SELECT datetime from animal_ins order by datetime desc limit 1
-- 2. 최솟값 구하기
SELECT min(datetime) from animal_ins
-- 3. 동물 수 구하기
SELECT count(animal_id) from animal_ins;
-- 4. 중복 제거하기
SELECT distinct(name) from animal_ins
-- 1. 고양이와 개는 몇마리 있을까
SELECT animal_type, count(animal_id) as count from animal_ins group by animal_type order by animal_type asc
-- 2. 동명 동물 수 찾기
SELECT name, count(name) as count from animal_ins group by name having count(name) >= 2 order by name asc
-- 3. 입양 시작 구하기 (1)
select HOUR(datetime) as hour, count(datetime) as count
from animal_outs
group by hour having hour >= 9 and hour < 20
order by hour asc
-- 4. 입양 시각 구하기 (2)
SET @h = -1;
SELECT (@h := @h + 1) as hour,
(select count(hour(datetime)) from animal_outs where hour(datetime) = @h) as count
from animal_outs where @h < 23
-- 1. 이름이 없는 동물의 아이디
SELECT animal_id from animal_ins where name is NULL
-- 2. 이름이 있는 동물의 아이디
SELECT animal_id from animal_ins where name is not null order by animal_id asc
-- 3. NULL 처리하기
SELECT animal_type, ifnull(name, "No name") as name, sex_upon_intake from animal_ins;
-- 1. 없어진 기록 찾기
SELECT outs.animal_id, outs.name from animal_outs outs
left outer join animal_ins ins
on outs.animal_id = ins.animal_id
where ins.animal_id is null
order by outs.animal_id asc
-- 2. 있었는데요 없었습니다
SELECT ins.animal_id, ins.name from animal_ins ins
join animal_outs outs on ins.animal_id = outs.animal_id
where ins.datetime > outs.datetime
order by ins.datetime asc
-- 3. 오랜 기간 보호한 동물 (1)
select ins.name, ins.datetime from animal_ins ins
left join animal_outs outs
on ins.animal_id = outs.animal_id
where outs.animal_id is null
order by ins.datetime asc
limit 3
-- 4. 보호소에서 중성화한 동물
SELECT ins.animal_id, ins.animal_type, ins.name from animal_ins ins
left join animal_outs outs
on ins.animal_id = outs.animal_id
where (outs.sex_upon_outcome like '%Spayed%' or outs.sex_upon_outcome like '%Neutered%')
and ins.sex_upon_intake like '%Intact%'
order by ins.animal_id asc
-- 1. 루시와 엘라 찾기
SELECT animal_id, name, sex_upon_intake from animal_ins
where name="Lucy" or name="Ella" or name="Pickle" or name="Rogan" or name="Sabrina" or name="Mitty"
order by animal_id asc
-- 2. 이름에 el이 들어가는 동물 찾기
SELECT animal_id, name from animal_ins
where lower(name) like "%el%" and animal_type = "Dog"
order by name asc
-- 3. 중성화 여부 파악하기
SELECT animal_id, name,
case when (SEX_UPON_INTAKE LIKE '%NEUTERED%' OR SEX_UPON_INTAKE LIKE '%SPAYED%')then 'O' else 'X' end
from animal_ins
order by animal_id asc
-- 4. 오랜 기간 보호한 동물 (2)
SELECT ins.animal_id, ins.name from animal_ins ins, animal_outs outs
where ins.animal_id = outs.animal_id
order by datediff(outs.datetime, ins.datetime) desc
limit 2
-- 5. DATETIME에서 DATE로 형 변환
SELECT animal_id, name, DATE_FORMAT(datetime, '%Y-%m-%d') as 날짜 from animal_ins
order by animal_id asc
def dfs(begin, target, words, visited):
str_end = target
str_start = begin
int_depth = 0
arr_stack = [str_start]
while arr_stack:
str_top = arr_stack.pop()
print(str_top)
if str_top == target:
return int_depth
for i in range(len(words)):
if visited[i] or words[i] == str_top:
continue
for _ in range(len(words[i])):
count_tmp = 0
for j in range(len(words[i])):
if [ch for ch in words[i]][j] == [ch for ch in str_top][j]:
count_tmp+=1
if (len(words[i])-1) == count_tmp:
visited[i] = True
if words[i] != str_end:
arr_stack.append(words[i])
else:
return int_depth+1
break
int_depth += 1
def solution(begin, target, words):
if target not in words:
return 0
visited = [False] * (len(words))
print(words)
return dfs(begin, target, words, visited)