1. 목적 및 내용 요약
Captcha 이미지를 읽어 내용을 알려주는 신경망 모델을 Python으로 작성하여 UiPath Activity 형태로 만들어준다.
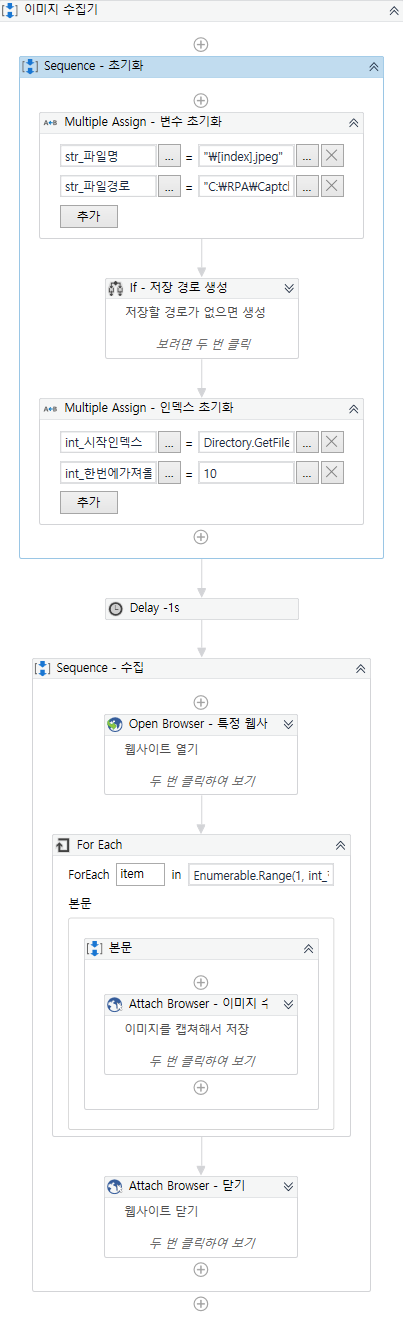
2. Captcha 이미지 수집기 제작

3. 이미지 Dataset 만들기
3-1) 폴더 구성
- C:\RPA\Captcha_ImageCollector\origin : 위에서 수집기가 수집한 파일들 위치
- C:\RPA\Captcha_ImageCollector\separate : 분리된 파일들 생성
- C:\RPA\Captcha_ImageCollector\complete : 분리가 완료된 파일 이동
3-2) 이미지 분리용 코드
import tensorflow as tf
import cv2
import os
import PIL.Image as pimage
import numpy as np
import matplotlib.image as mimage
import matplotlib.pyplot as plt
from tensorflow.keras import datasets, layers, models
# Init Flag
is_Debug = False
# Init global variables
str_path_main = "C:\RPA\Captcha_ImageCollector"
str_path_origin = str_path_main + "\\origin"
str_name_origin = "\\[index].jpeg"
str_file_origin = str_path_origin + str_name_origin
str_path_separate = str_path_main + "\\separate"
str_name_separate = "\\[index].jpeg"
str_file_separate = str_path_separate + str_name_separate
str_path_complete = str_path_main + "\\complete"
str_path_dataset = str_path_main + "\\dataset"
str_path_testset = str_path_main + "\\testset"
# 입력 경로의 파일 수를 반환
def get_current_index(str_path):
return len(os.listdir(str_path))
# 이미지 Shape를 출력
def print_ImageShape(img, is_debug):
if is_debug:
_height, _width, _channel = img.shape
print("Image Shape : " + str(_height) +", "+ str(_width) + ", " + str(_channel))
# 분리된 이미지를 생성
def Image_Separate(str_originImage):
# separate 경로 내부의 현재 파일 수를 얻어옴
int_index = get_current_index(str_path_separate)
# 이미지 사이즈 변수 초기화
origin_w = 240 # 6*40
origin_h = 120 # 6*20
piece_x = int(origin_w/7)
# 원본 이미지 불러오기
img = cv2.imread(str_originImage)
print_ImageShape(img, is_Debug)
# 이미지 사이즈 변경 후 테두리 공백 제거
img = cv2.resize(img, dsize=(origin_w, origin_h)).copy()
img = img[int(origin_h*0.05):int(origin_h*0.75), int(origin_w*0.05):int(origin_w*0.90)].copy()
print_ImageShape(img, is_Debug)
# 이미지 분리
list_img = []
img_copy = img.copy()
for i in range(0, 6):
list_img.append(img[:, piece_x * i:piece_x * (i+1)])
if is_Debug:
# 디버그 모드일 경우 분리할 경계선을 보라색으로 나타내줌
result = cv2.rectangle(img_copy, (piece_x * i, 0), (piece_x * i, origin_h), (255, 0, 255), 1)
print(piece_x * i, ", ", piece_x*(i+1))
# 분리된 이미지를 separete 경로에 파일로 출력, 뒤로 이어붙이기
for i in range(0, 6):
int_index = int_index + 1
cv2.imwrite(str_file_separate.replace("[index]", str(int_index)), list_img[i])
if is_Debug:
cv2.imshow('img', list_img[i])
cv2.waitKey(0)
if is_Debug:
result = img_copy
cv2.imshow('result', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
return ;
# Function
def Start_Separate():
# 한번에 가져올 개수, 아래 코드는 현재 경로에 있는 파일 전부를 의미함
int_onetime = get_current_index(str_path_origin)
last_origin_index = get_current_index(str_path_origin)
last_complete_index = get_current_index(str_path_complete)
print("origin start count: ", last_origin_index)
print("complete start count : ", last_complete_index)
# origin의 마지막 index 파일부터 가져옴 (수집기가 뒤에서부터 추가하기 때문)
for i in reversed(range(last_origin_index + 1 - int_onetime, last_origin_index + 1)):
str_ImageFullPath = str_file_origin.replace("[index]" , str(i))
try:
print(str_ImageFullPath)
Image_Separate(str_ImageFullPath)
print(str_path_complete + "\\" + str(i)+".jpeg")
last_complete_index += 1
os.rename(str_ImageFullPath, str_path_complete + "\\" + str(last_complete_index) +".jpeg")
except:
print(str_ImageFullPath + " - 파일 없음.")
last_origin_index = get_current_index(str_path_origin)
last_complete_index = get_current_index(str_path_complete)
print("origin end count: ", last_origin_index)
print("complete end count : ", last_complete_index)
# 분리 시작
Start_Separate()
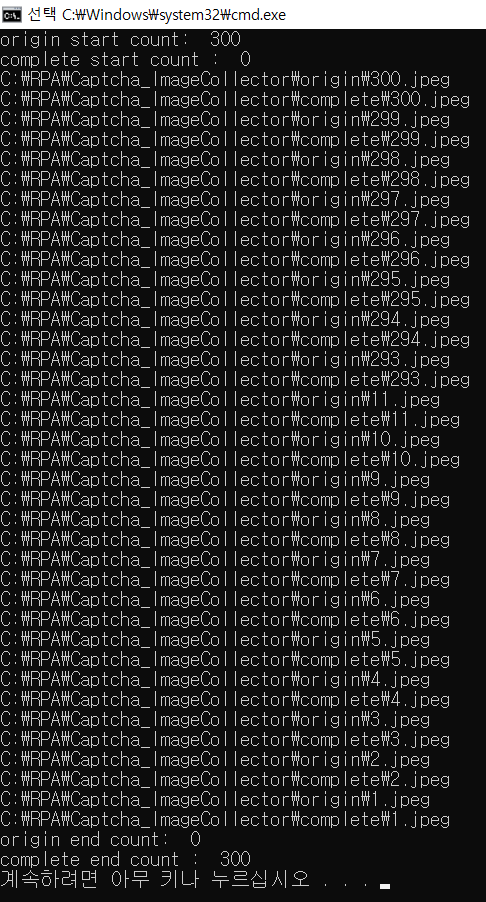
3-3) 결과
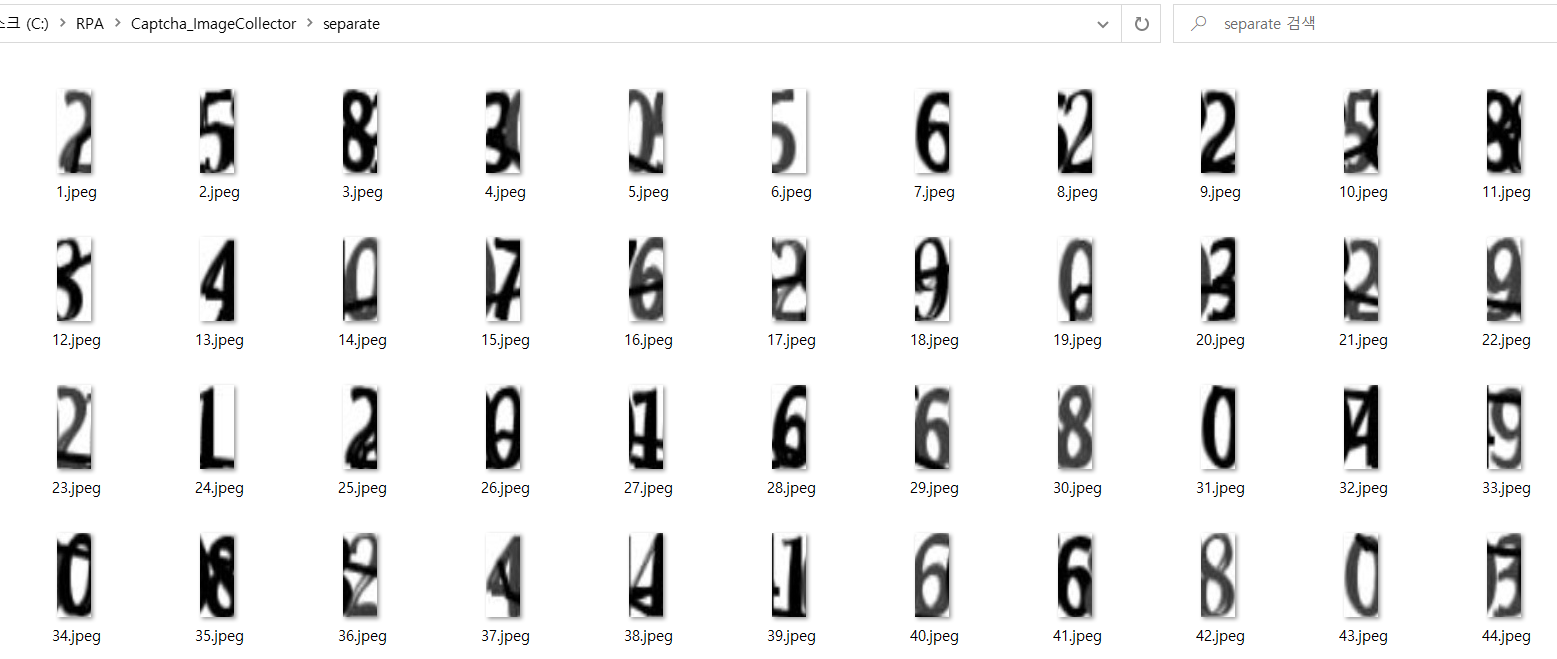
3-4) 이미지 분류
- 이미지 내부의 숫자들 중 괜찮은 이미지를 각 숫자별 폴더로 분류
- 불량한 애들은 수작업으로 버려줌
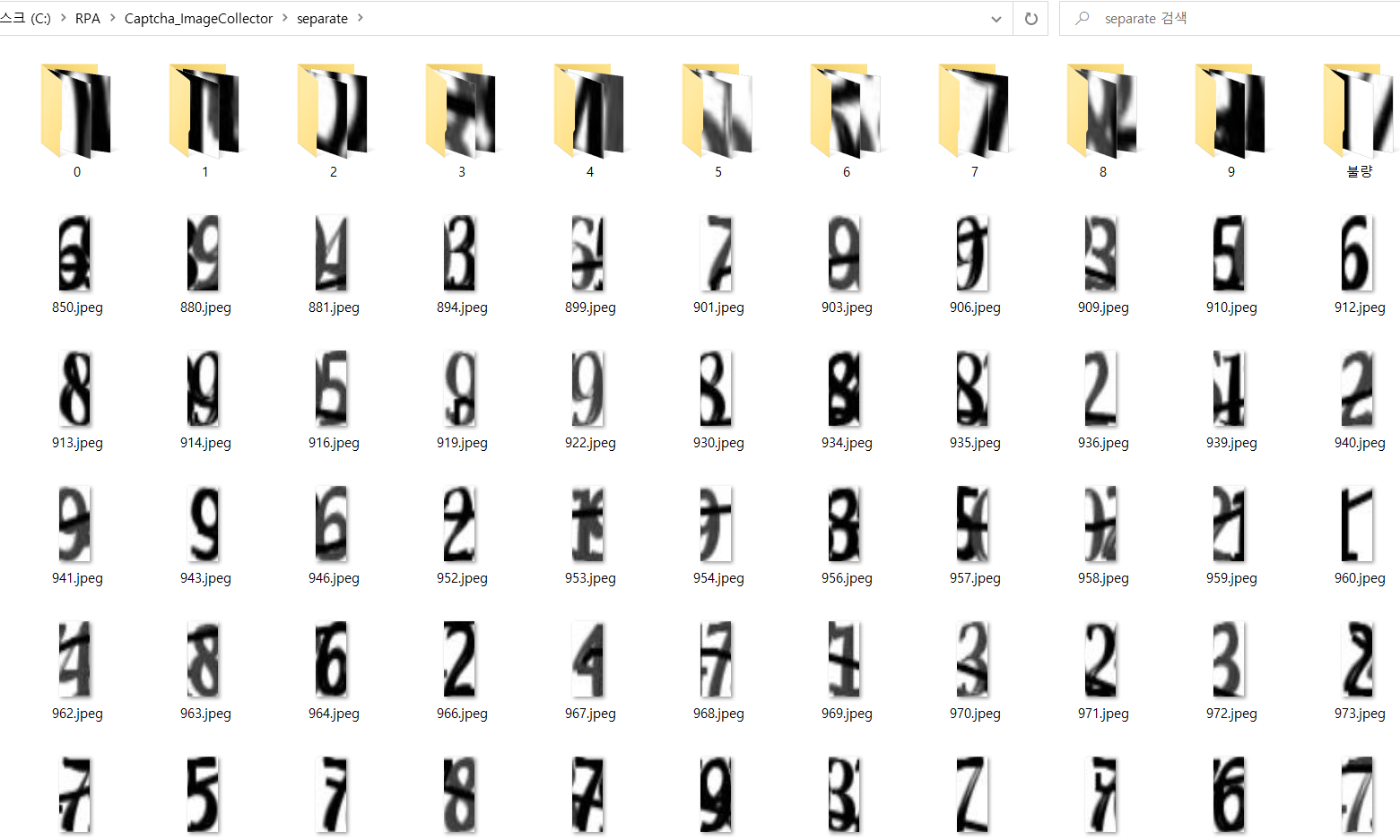
4. 학습 모델 제작, 학습, 가중치 파일 생성
- C:\RPA\Captcha_ImageCollector\dataset : 학습 시 사용할 데이터들, 폴더 별로 분류된 이미지들이 위치
- C:\RPA\Captcha_ImageCollector\testset : 학습 완료 후 정확도를 검증하기 위한 테스트용 데이터 위치
- 위 분리용 코드 이어서 작성
4-1) 학습용 코드
# 한개 이미지 가져와서 테스트
def test_OneImage(model, image_path):
x = []
img = cv2.imread(image_path, 0)
cv2.imshow("current image", img)
cv2.waitKey(0)
tmp_x = cv2.resize(img, dsize = (84, 34))
tmp_x = tmp_x.astype('int32')
tmp_x = tmp_x.reshape(84, 34, 1)
tmp_x = tmp_x / 255.0
x.append(tmp_x)
predicted_number = model.predict_classes(np.array(x))[0]
return predicted_number
# 데이터셋 가져오기
def get_datasets(str_dataset_path):
dataset_images = []
dataset_labels = []
for i in range(0, 10):
for j in range(1, 100):
img_name = str_dataset_path + "\\" + str(i) + "\\" + str(i) + " (" + str(j) + ").jpeg"
try:
img = cv2.imread(img_name, 0)
x = cv2.resize(img, dsize = (84, 34))
x = x.astype('int32')
x = x.reshape(84, 34, 1)
x = x / 255.0
dataset_images.append(x)
dataset_labels.append(i)
except:
None
return dataset_images, dataset_labels
# CNN 모델
def model_CNN_ver1():
# model
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(84, 34, 1)))
model.add(layers.MaxPooling2D((2, 2)))
#model.add(layers.Dropout(0.5))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Dropout(0.5))
# dense layer
model.add(layers.Flatten())
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
# 데이터셋, 테스트셋 가져오기
train_images, train_labels = get_datasets(str_path_dataset)
test_images, test_labels = get_datasets(str_path_testset)
print("가져온 학습용 데이터 수 : ", len(train_images))
print("가져온 테스트용 데이터 수 : ", len(test_images))
# 모델 생성
model = model_CNN_ver1()
# 모델 8회 학습
model.fit(np.array(train_images), np.array(train_labels), epochs=8)
model.save("my_model.h5")
# h5 파일 가져와서 정확도 테스트
model22 = models.load_model("my_model.h5")
# 3회 정확도 테스트
test_loss, test_acc = model.evaluate(np.array(test_images), np.array(test_labels), verbose=3)
print("학습된 모델의 정확도 : {:5.2f}%".format(100*test_acc))
4-2) 학습 결과
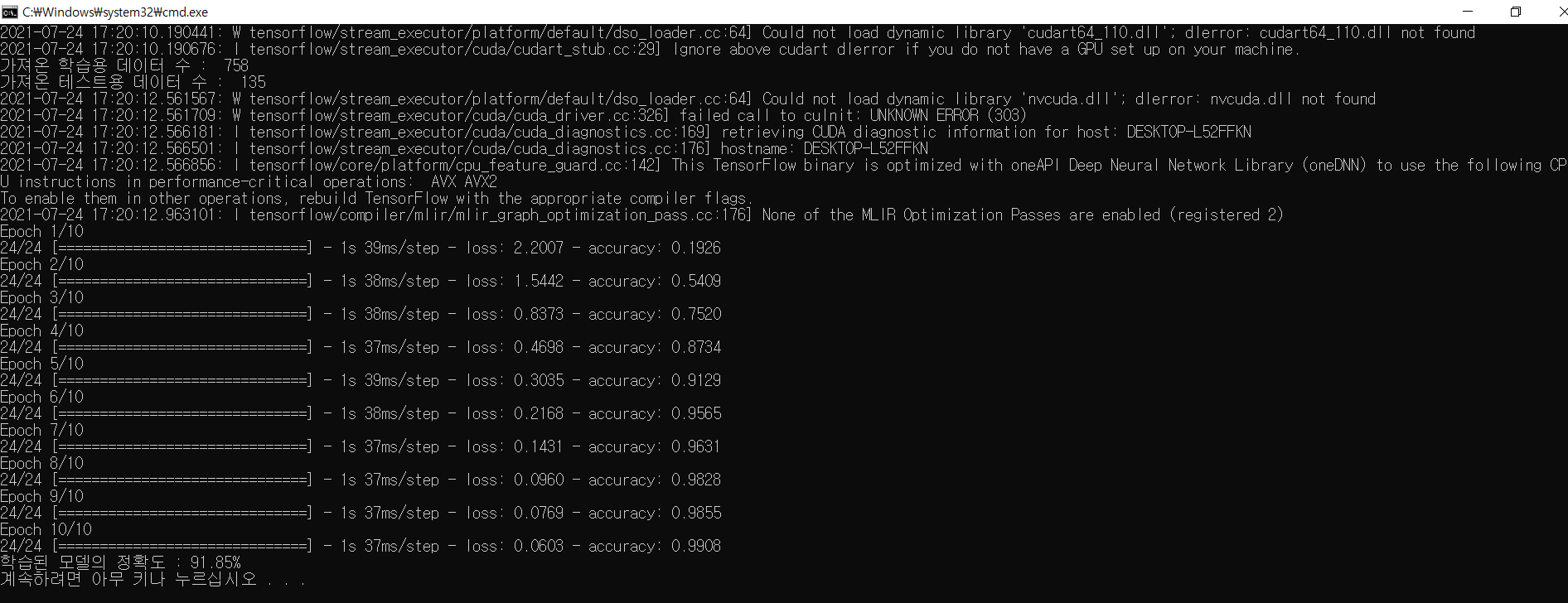
- 대충 10번의 학습 후에 91.85%의 테스트 정확도를 가지는 my_model.h5 가중치, 모델 파일이 생성됨.
4-3) 가중치 파일 사용해서 정확도 테스트하기
test_images, test_labels = get_datasets(str_path_testset)
print("가져온 테스트용 데이터 수 : ", len(test_images))
# 모델 생성
model = model_CNN_ver1()
# 파일을 불러오지 않고 모델의 정확도 테스트
test_loss, test_acc = model.evaluate(np.array(test_images), np.array(test_labels), verbose=3)
print("학습안된 모델의 정확도 : {:5.2f}%".format(100*test_acc))
# h5 파일 가져온 뒤 정확도 테스트
model22 = models.load_model("my_model.h5")
test_loss, test_acc = model22.evaluate(np.array(test_images), np.array(test_labels), verbose=3)
print("학습된 모델의 정확도 : {:5.2f}%".format(100*test_acc))
4-4) 테스트 결과

4-5) 이미지 한개씩 가져와서 예측된 값 보기
model22 = models.load_model("my_model.h5")
for i in range(0, 10):
for j in range(1, 100):
imgname = str_path_testset + "\\" + str(i) + "\\" + str(i) + " (" + str(j) + ").jpeg"
try:
print(test_OneImage(model22, imgname))
except:
print("no image files")
None
4-6) 결과
- 중간 중간 잘못 예측된 결과가 보인다. 그냥 진행한다.

5. 원본 이미지 넣어서 한번에 결과 보기
5-1) 테스트용 원본 이미지, 학습 파일 경로 지정

5-2) 코드
# Image_Separate 기반, 6조각으로 분리된 이미지 자체를 return
def Image_Separate_2(str_originImagePath):
# init
origin_w = 240 # 6*40
origin_h = 120 # 6*20
piece_x = int(origin_w/7)
# Read Image
img = cv2.imread(str_originImagePath, 0)
img = cv2.resize(img, dsize=(origin_w, origin_h)).copy()
img = img[int(origin_h*0.05):int(origin_h*0.75), int(origin_w*0.05):int(origin_w*0.90)].copy()
# Separated Image
list_img = []
for i in range(0, 6):
list_img.append(img[:, piece_x * i:piece_x * (i+1)])
return list_img;
# 이미지를 받아서 예측 값 retrun
def test_OneImage_2(model, img):
x = []
tmp_x = cv2.resize(img, dsize = (84, 34))
tmp_x = tmp_x.astype('int32')
tmp_x = tmp_x.reshape(84, 34, 1)
tmp_x = tmp_x / 255.0
x.append(tmp_x)
predicted_number = model.predict_classes(np.array(x))[0]
return predicted_number
# 분리된 이미지 list를 하나씩 넣어서 결과값 list를 만듦
def completed_module(my_model, img_path):
list_img_2 = Image_Separate_2(img_path)
list_result = []
for int_index in range(0, 6):
list_result.append(test_OneImage_2(my_model, list_img_2[int_index]))
return list_result;
def test_FullImage():
oringin_img_path = "test (" + str(int_index) + ").jpeg"
for int_index in range(1, 400):
try:
# 결과 출력
print(completed_module(model22, oringin_img_path)
# 원본 이미지 보여주기
origin_img = cv2.imread(oringin_img_path)
cv2.imshow("result", origin_img)
cv2.waitKey(0)
except:
None
# 테스트
test_FullImage()
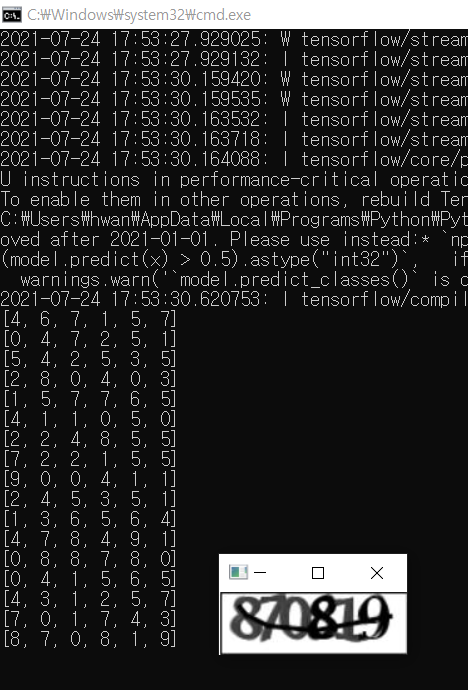
5-3) 결과
- 체감상 70~80% 확률로 성공
6. 학습된 가중치 파일 c#에서 실행하기
- HDF.Invoke, IronPython, Keras.Net, Tensorflow.Net 으로 코드 테스트해본 결과,
정상동작하지 않거나 라이브러리 종속성 문제, 파이썬 3 지원안함 등의 문제로 사용 제한됨
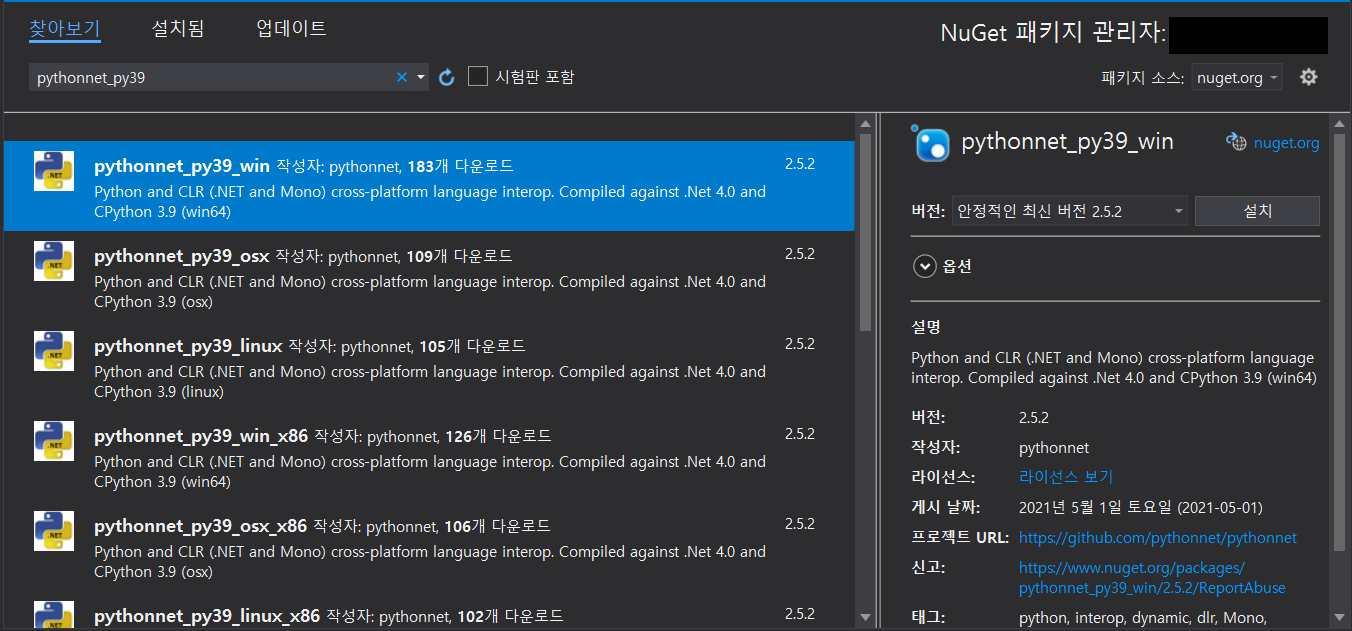
-> 현재사용하는 python39버전과 PythonNet Nuget의 버전을 맞춰서 설치함
- 위에서 작성된 코드를 클래스 형태로 재작성
- 파이썬 코드와 h5 모듈은 실행되는 파일과 동일폴더에 위치하여야 함
(VS의 속성 창에서 해당 파일 우클릭 > 속성 > 파일복사 칸의 값을 항상 복사로 설정하면
실행 시마다 해당 파일이 실행 파일 옆에 복사됨)
- 이 과정은 C#-Python 연동을 위한 테스트 코드 부분임
Activity 제작 관련 내용은 아래 7번 항목으로 이동
6-1) C# 코드 (PythonNet)
using System;
using System.Text;
using System.IO;
using Python.Runtime; // PythonNet - python39버전 설치
using System.Collections.Generic;
namespace ConsoleApp2
{
class Program
{
static void Main(string[] args)
{
// 엔진 초기화
PythonEngine.Initialize();
// 정확하진 않지만 자원을 동결시켜 준다고함
using (Py.GIL())
{
// Import할 모듈명, HwanCaptchaModule.py
dynamic hcm = Py.Import("HwanCaptchaModule");
// 임포트한 모듈 내부의 Hwan_Captcha_Module 클래스 초기화
dynamic f = hcm.Hwan_Captcha_Module("cur.jpeg", "my_model.h5");
// 클래스 내의 start 메소드 실행 후 결과 출력
Console.WriteLine(f.start());
}
// 엔진 종료
PythonEngine.Shutdown();
Console.WriteLine("Press any key...");
Console.ReadKey();
}
}
}
6-2) Python 코드
# -*- coding: utf-8 -*-
import os
# 로그 레벨 설정으로 Tensorflow 경고 문구 제거, Tensorflow를 import하기 전에 변경해 줘야한다.
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import sys
import cv2
import numpy as np
from tensorflow.keras import models
# Input : str_ImagePath, str_modelPath
# Output : str_result
class Hwan_Captcha_Module(object):
def __init__(self, str_ImagePath, str_modelPath):
self.str_ImagePath = str_ImagePath
self.str_modelPath = str_modelPath
self.model = models.load_model(self.str_modelPath)
def Image_Classification(self, img):
# 신경망에 넣기 전 데이터 형태 가공
x = []
tmp_x = cv2.resize(img, dsize = (84, 34)).astype('int32').reshape(84, 34, 1) / 255.0
x.append(tmp_x)
# predict로 반환된 SoftMax 값들을 리스트 형태로 바꾸어 그 중 가장 높은 확률의 인덱스를 구함
list = self.model.predict(np.array(x)).tolist()[0][:]
list = list.index(max(list))
# 찾아낸 인덱스가 신경망이 판단한 현재 이미지와 가장 가까운 숫자임
return list
def completed_module(self):
origin_w = 240 # 6*40
origin_h = 120 # 6*20
piece_x = int(origin_w/7)
# 흑백 이미지로 로드(이미지의 차원을 줄임)
img = cv2.imread(self.str_ImagePath, 0)
img = cv2.resize(img, dsize=(origin_w, origin_h))
# 주변 공백 제거
img = img[int(origin_h*0.05):int(origin_h*0.75), int(origin_w*0.05):int(origin_w*0.90)]
str_result = ""
# 위에서 계산된 한 조각 크기만큼 옆으로 이동하면서 숫자 이미지를 가져옴.
for i in range(0, 6):
str_result += str(self.Image_Classification(img[:, piece_x * i:piece_x * (i+1)]))
return str_result;
# 찾아낸 결과를 return 하고 에러 발생 시 문자열 return
def start(self):
try:
return self.completed_module()
except:
return "파일을 찾을 수 없습니다."
if __name__ == "__main__":
Hwan_Captcha_Module(sys.argv[1], sys.argv[2]).start()
6-3) 결과
- 한글자씩 틀리는 경우가 종종 있지만 대부분 성공 (체감상 60~70% 성공률인 듯 하다)
- 아래 411050은 마지막이 0인지 9인지 사람이 봐도 헷갈림




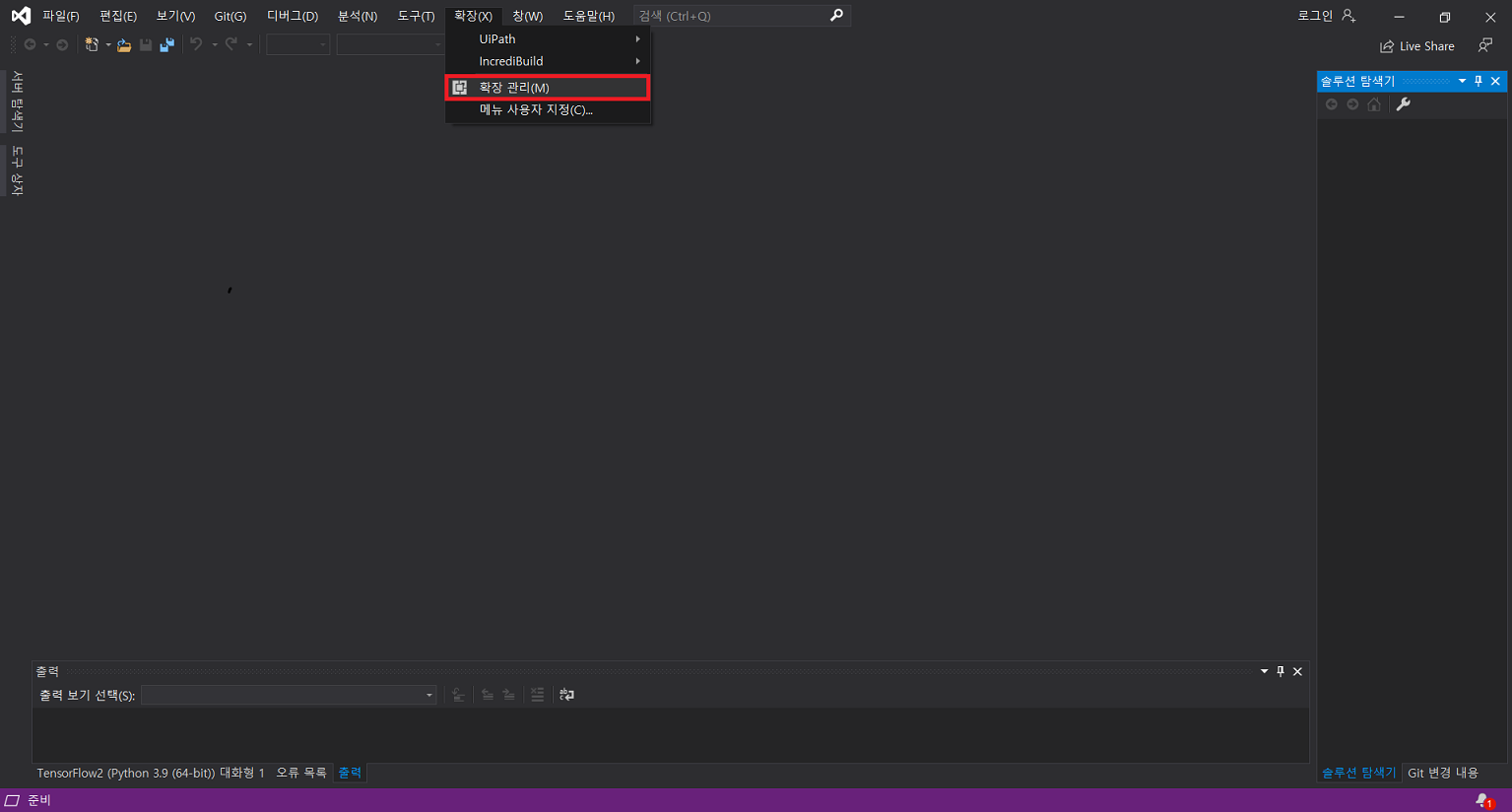
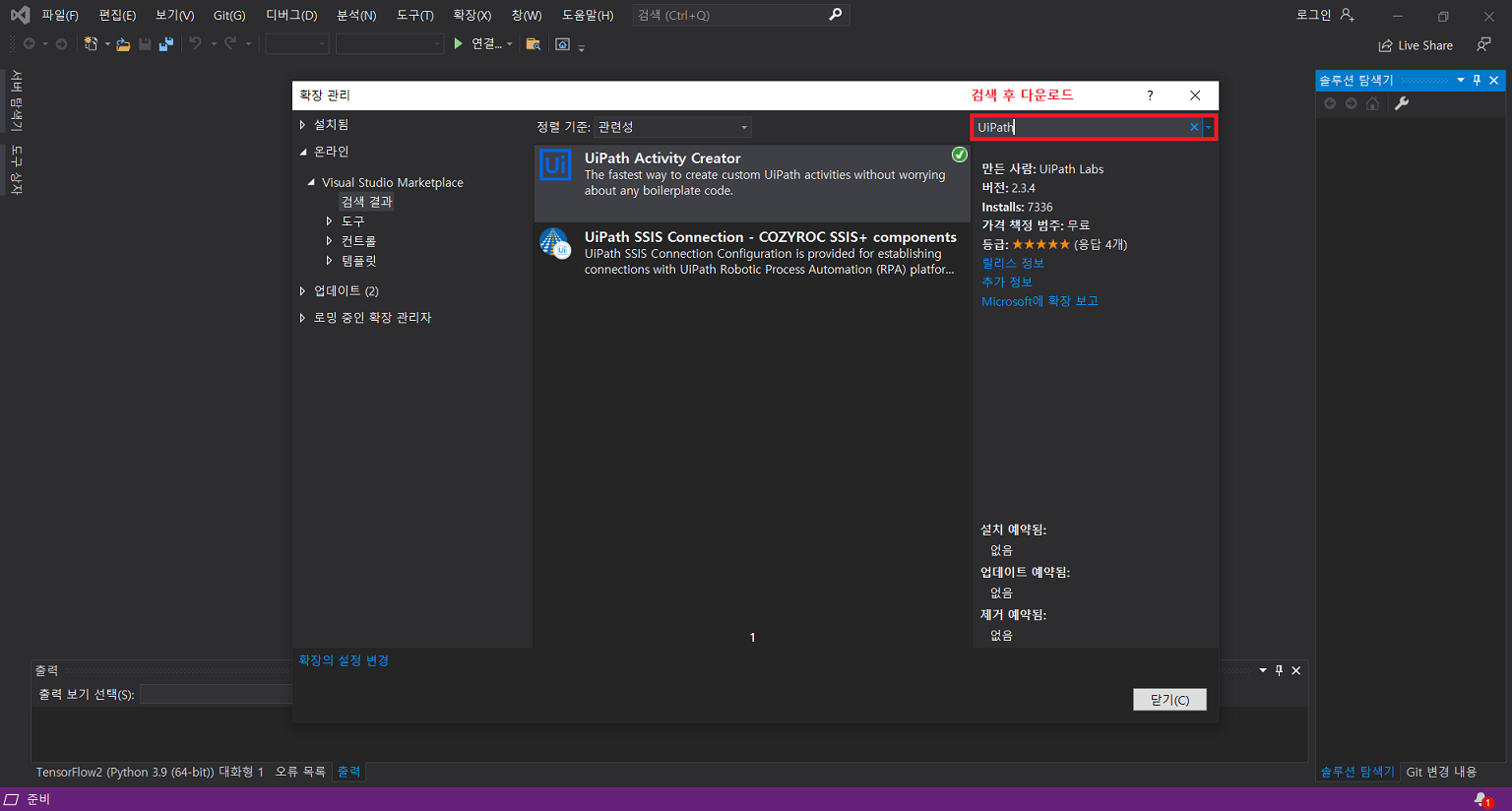
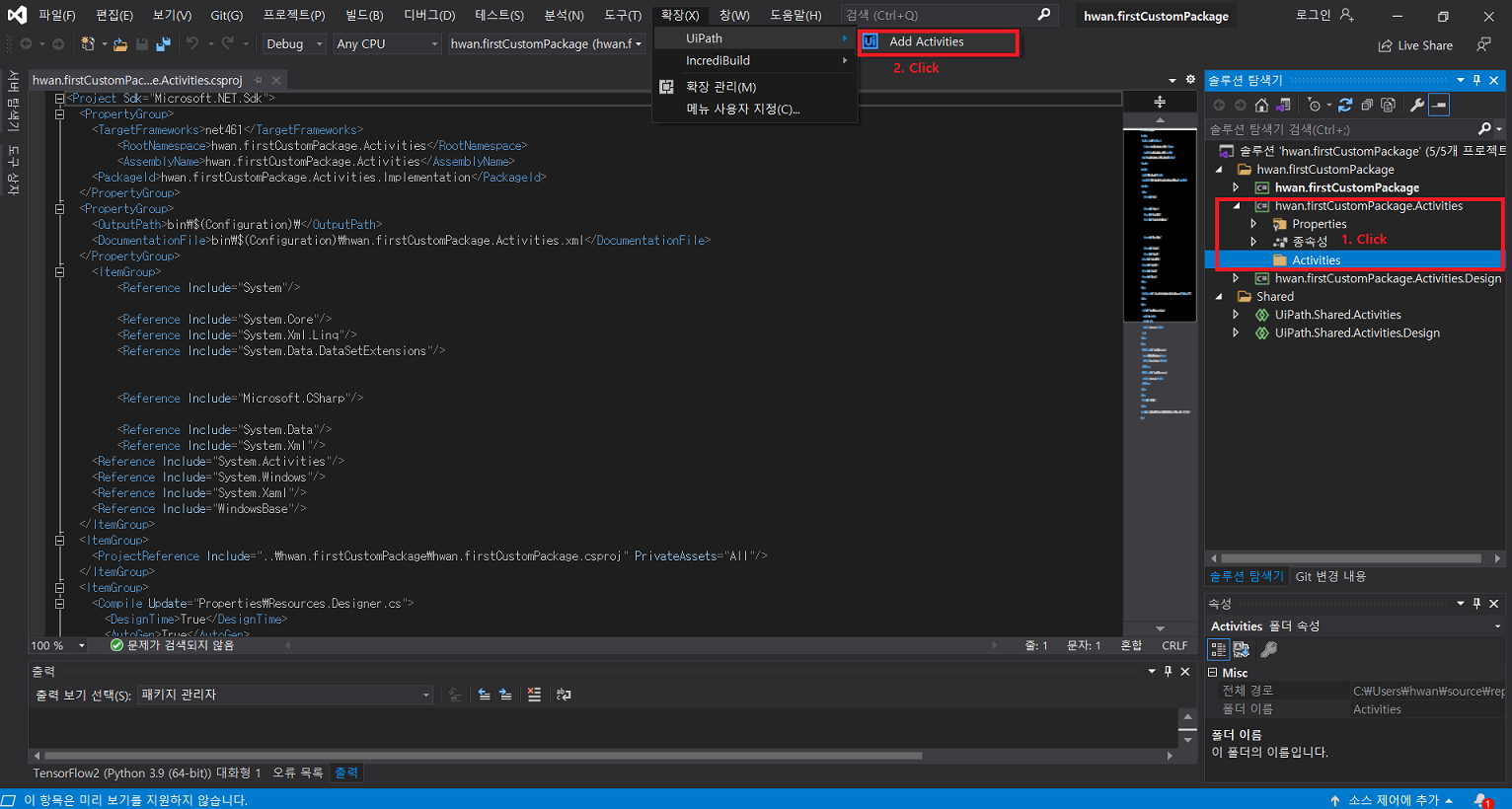
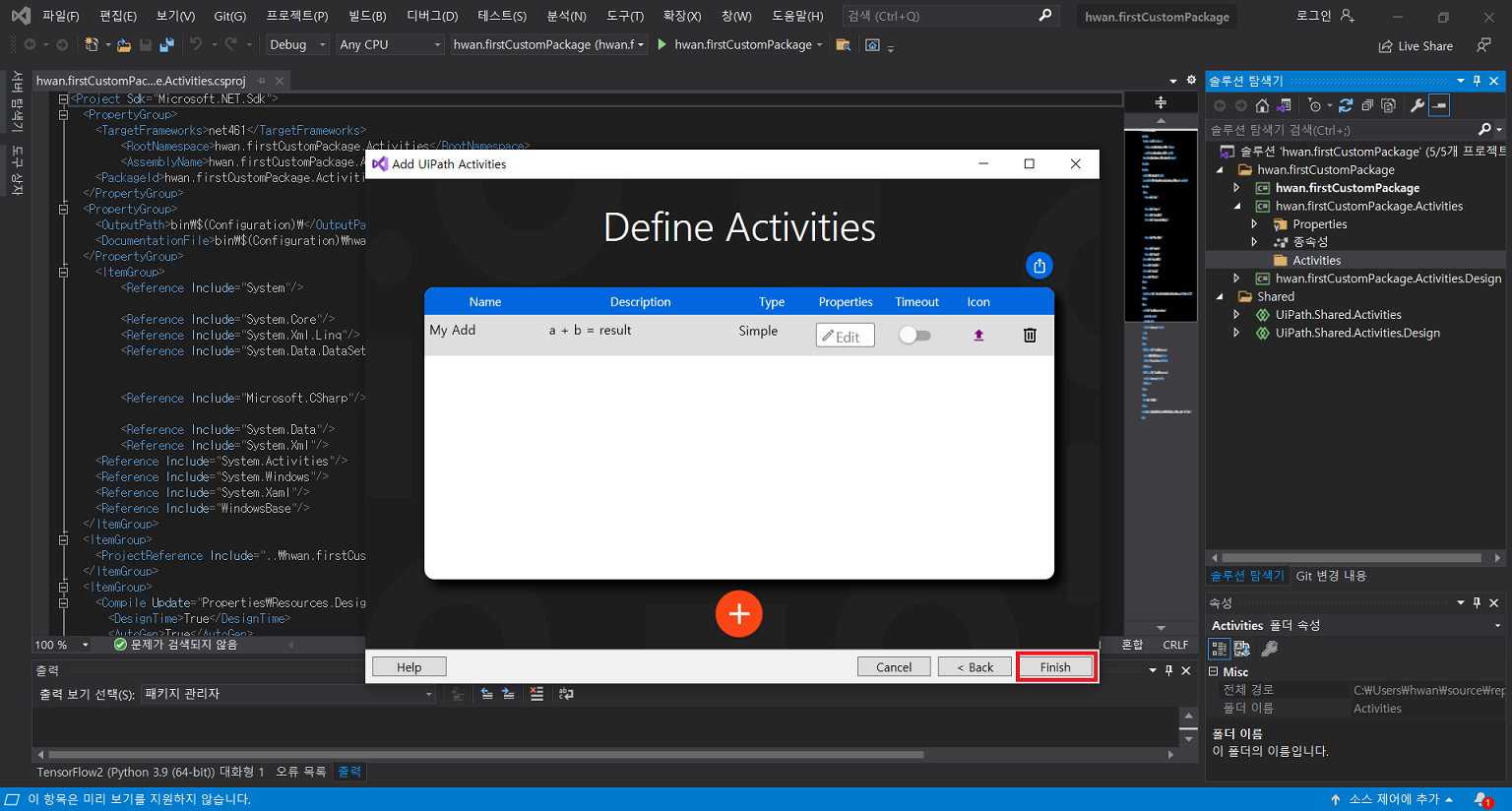
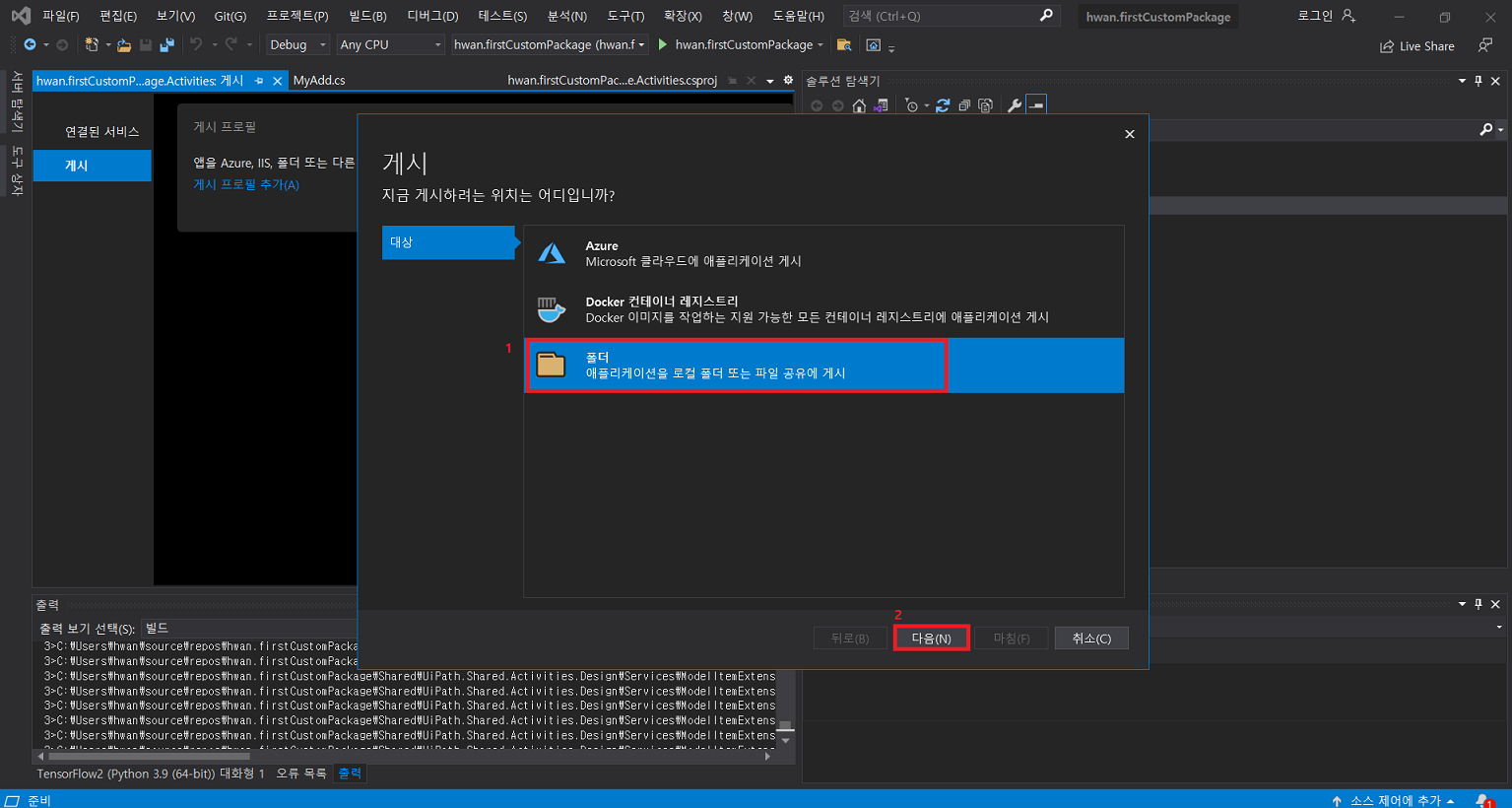
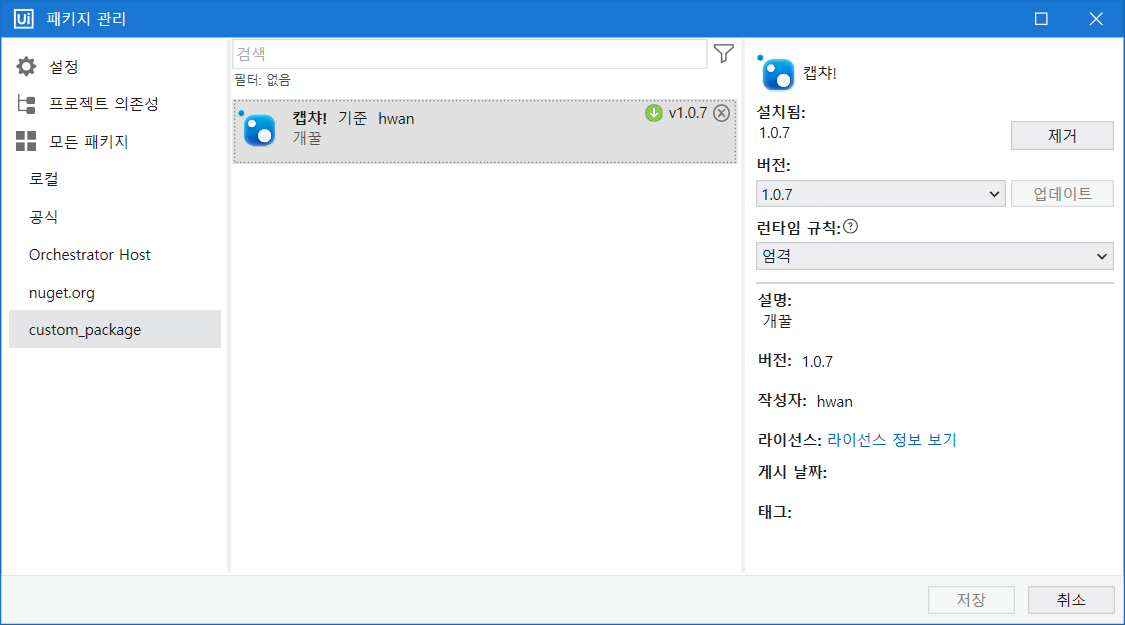
7. Custom Activity 제작
- Nuget Package Manager.exe 또는 Nuget.exe를 활용하여 .nupkg 파일 생성
- python 코드의 종속성을 없애기 위해 6번의 코드를 one directory - exe 형태로 만든 뒤 nupkg에 포함시킴
(auto-exe-to-py 환경 구성 및 사용법)
- nuspec 파일로 패키지 구성을 정의할 수 있음 (자세한 내용은 MSDN 참조)
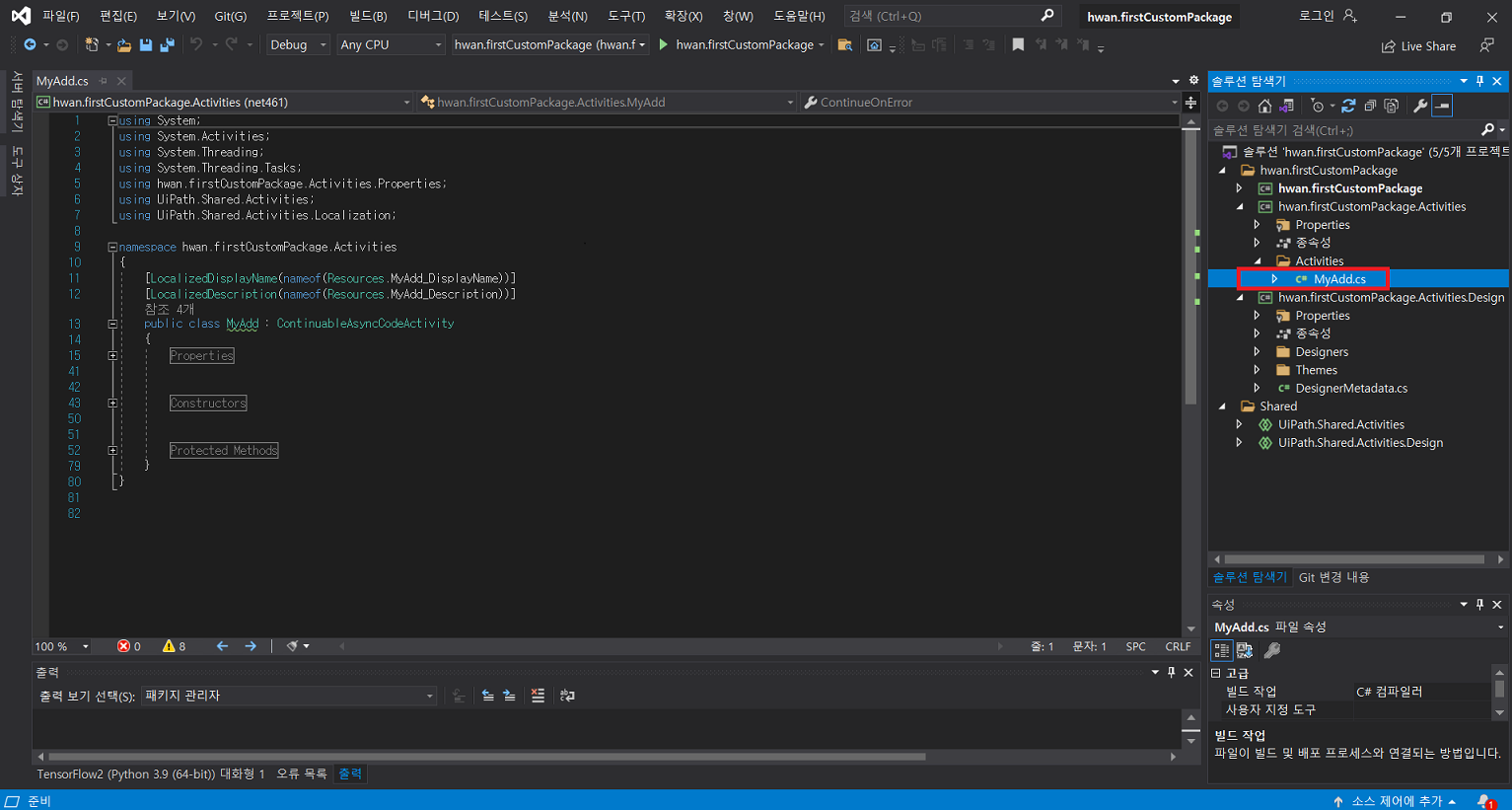
7-1) C# 코드 (C# 클래스 라이브러리, .Net Framework 4.6.1)
using System;
using System.IO;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Activities;
using System.ComponentModel;
using System.Diagnostics;
namespace ClassLibrary
{
public class Captcha : CodeActivity
{
[Category("Input")]
[RequiredArgument]
public InArgument<String> in_str_imagepath { get; set; }
[Category("Output")]
public OutArgument<String> out_str_result { get; set; }
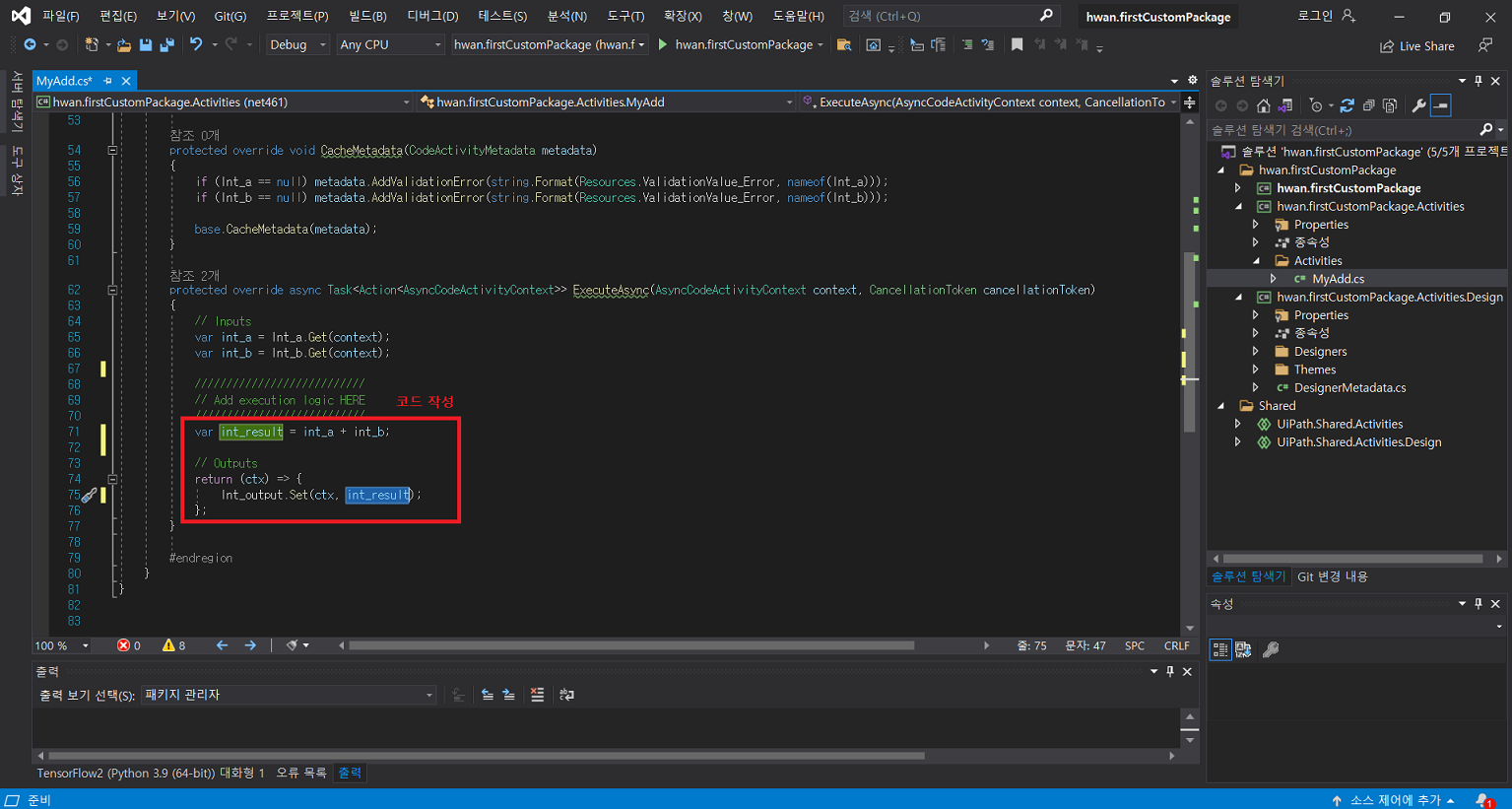
protected override void Execute(CodeActivityContext context)
{
var str_imagepath = in_str_imagepath.Get(context);
var str_result = "";
var str_error = "";
var str_id = "activities_captcha";
var str_version = "1.0.7";
var psi = new ProcessStartInfo();
var str_h5file = Environment.GetEnvironmentVariable("userprofile") + "\\.nuget\\packages\\"+ str_id + "\\"+ str_version + "\\hcm\\model.h5";
psi.FileName = Environment.GetEnvironmentVariable("userprofile") + "\\.nuget\\packages\\" + str_id + "\\" + str_version + "\\hcm\\Hwan_Captcha_Module.exe";
psi.Arguments = string.Format("{0} {1}", str_imagepath, str_h5file);
psi.UseShellExecute = false;
psi.RedirectStandardOutput = true;
psi.RedirectStandardError = true;
using (var process = Process.Start(psi))
{
str_error = process.StandardError.ReadToEnd();
str_result = process.StandardOutput.ReadToEnd();
// 에러가 비어있지 않으면 에러 출력
if (!string.IsNullOrEmpty(str_error))
{
Console.WriteLine("error : " + str_error);
}
}
out_str_result.Set(context, str_result);
}
}
}
7-2) .nuspec 파일 생성
<?xml version="1.0" encoding="utf-8"?>
<package >
<metadata>
<id>activities_captcha</id>
<version>1.0.7</version>
<title>캡챠!</title>
<authors>hwan</authors>
<requireLicenseAcceptance>false</requireLicenseAcceptance>
<license type="expression">MIT</license>
<description>개꿀</description>
<releaseNotes>Summary of changes made in this release of the package.</releaseNotes>
<tags>Captcha</tags>
</metadata>
<files>
<file src="Hwan_Captcha_Module\**" target="hcm\" />
</files>
</package>
7-3) nuget.exe로 .nupkg 파일 생성하기
- nuget 파일 알아서 구하고 c:\windows 안에 두기
- nuspec있는 프로젝트 위치로 이동 후 아래 코드 실행
nuget pack
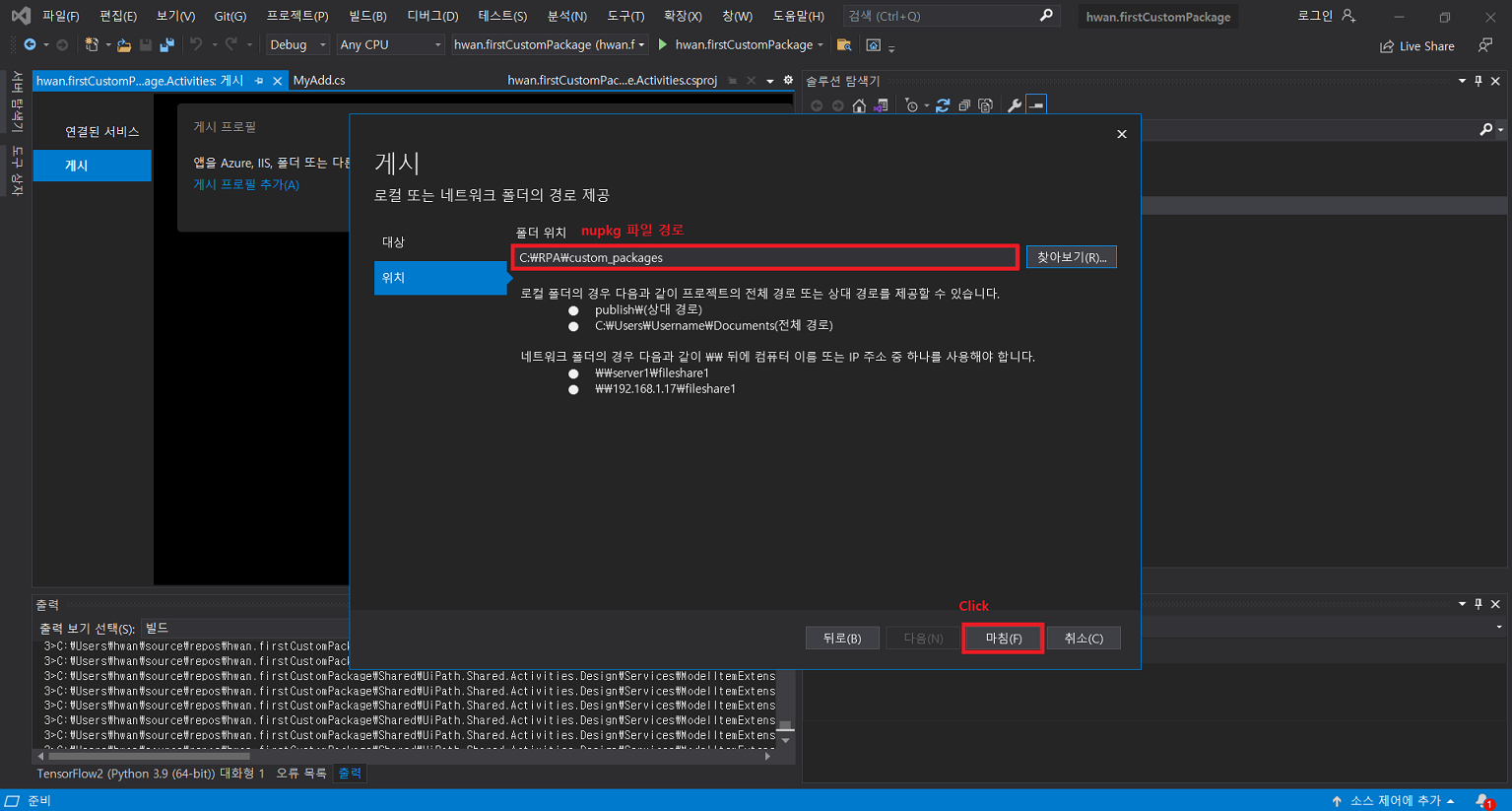
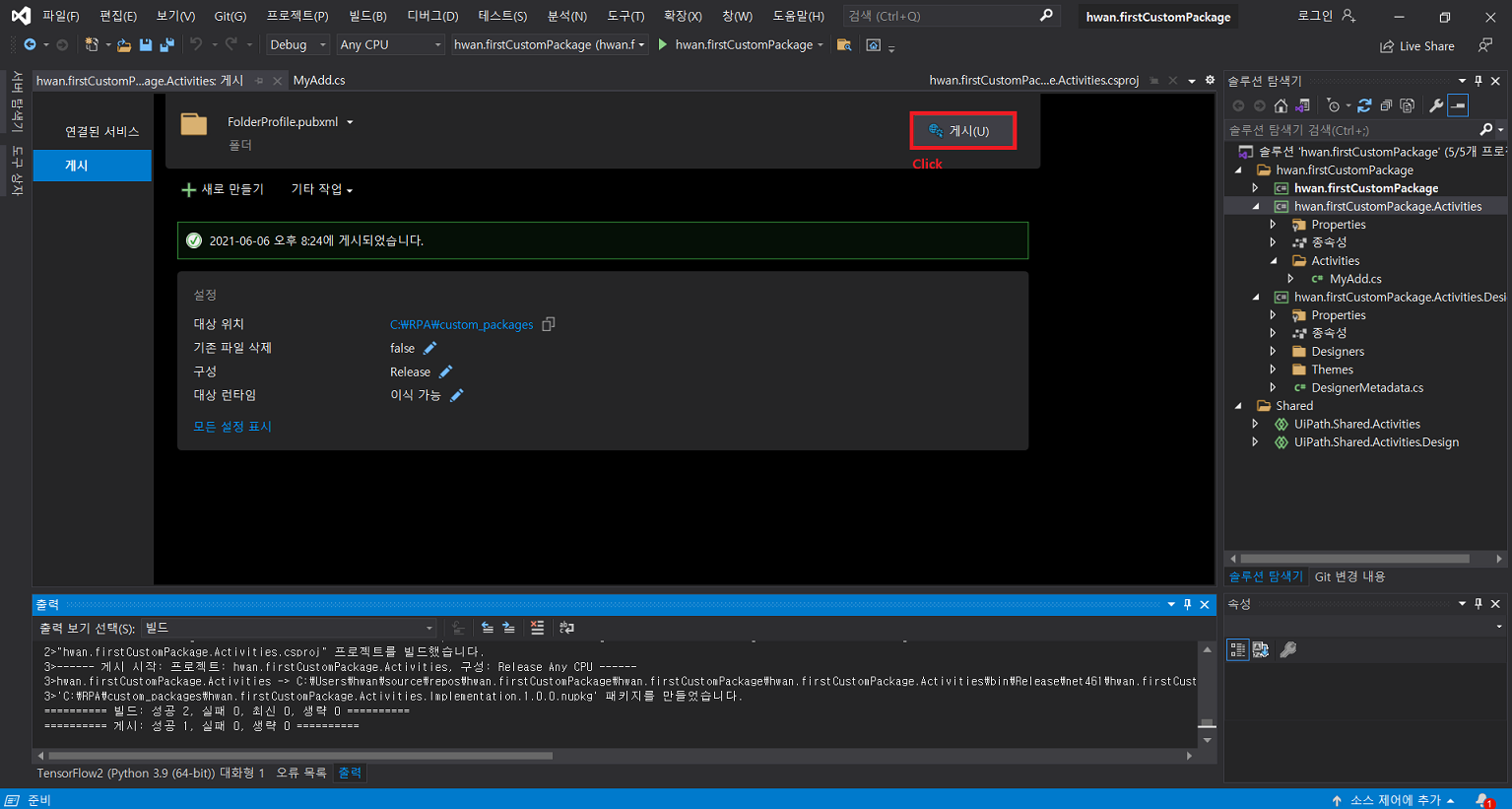
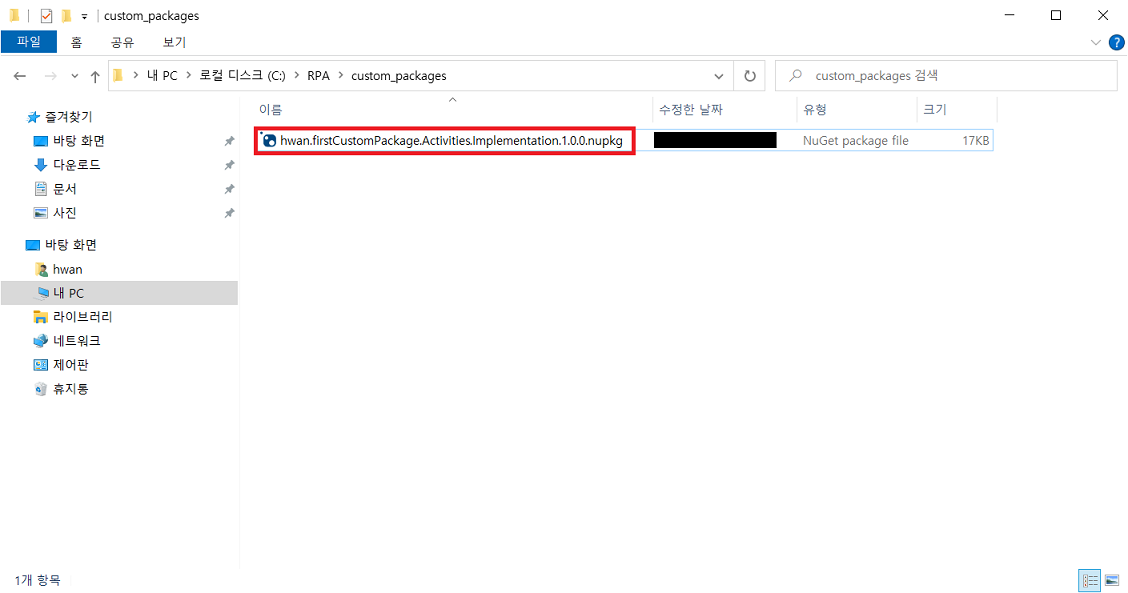
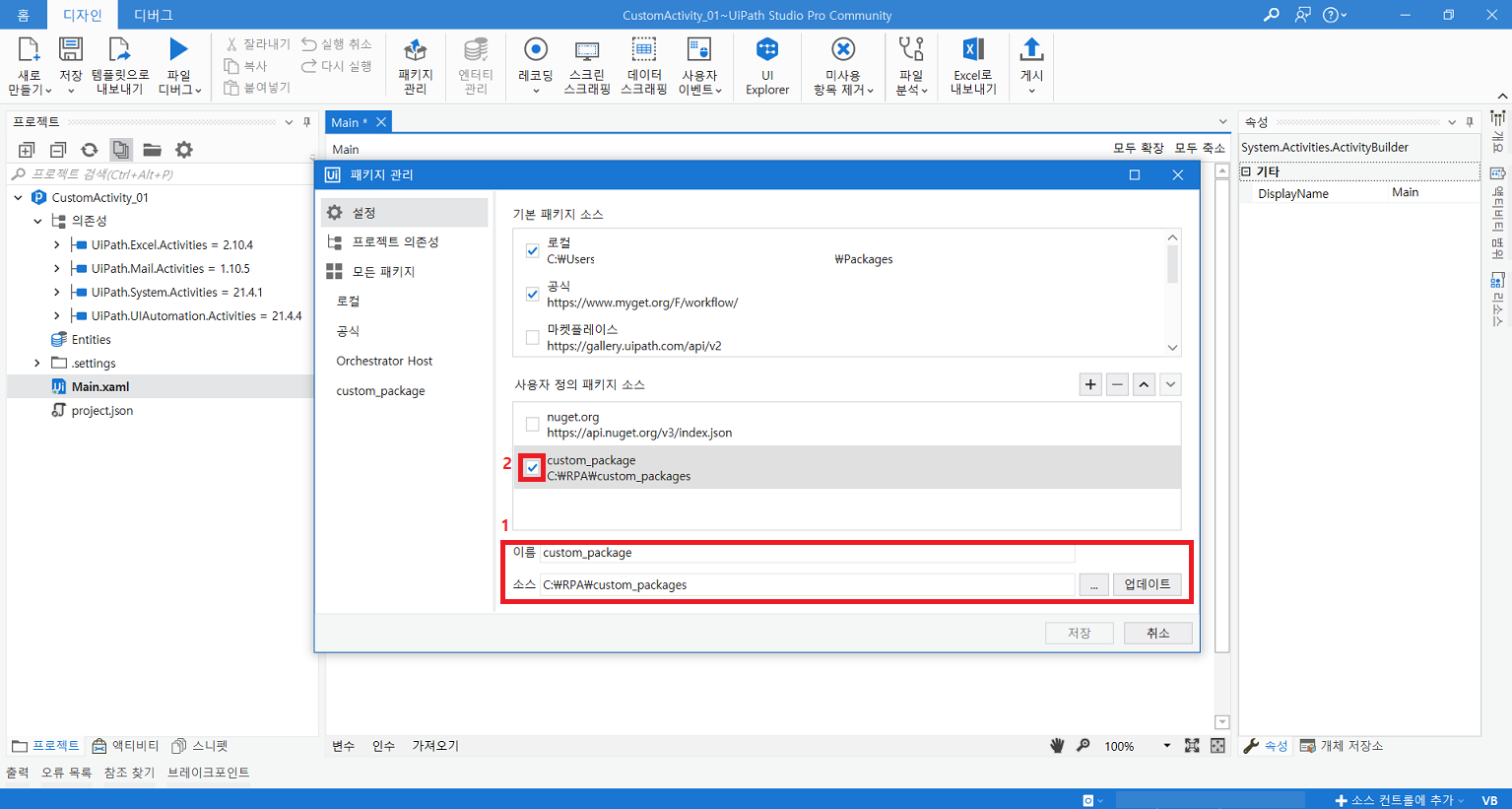
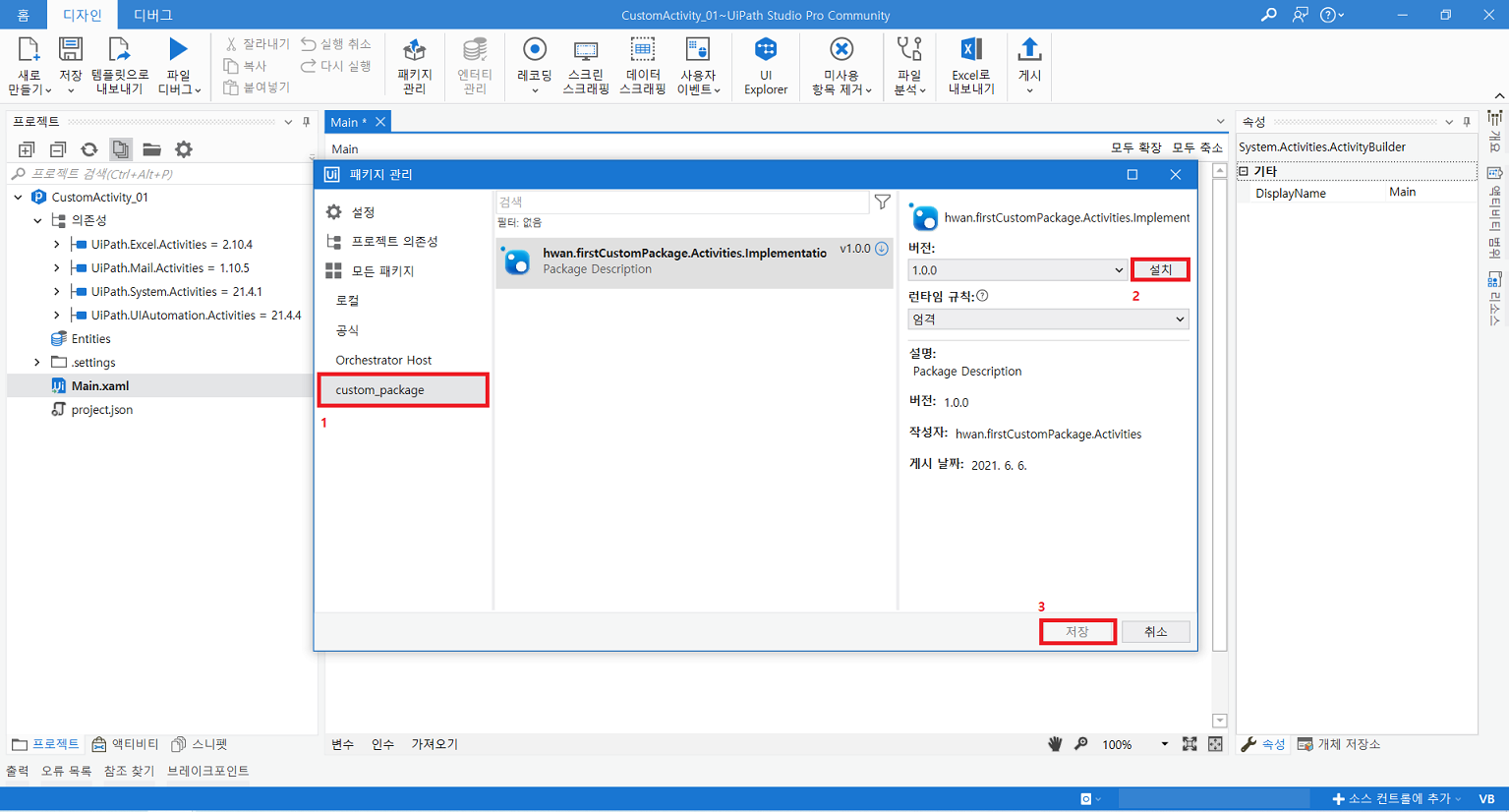
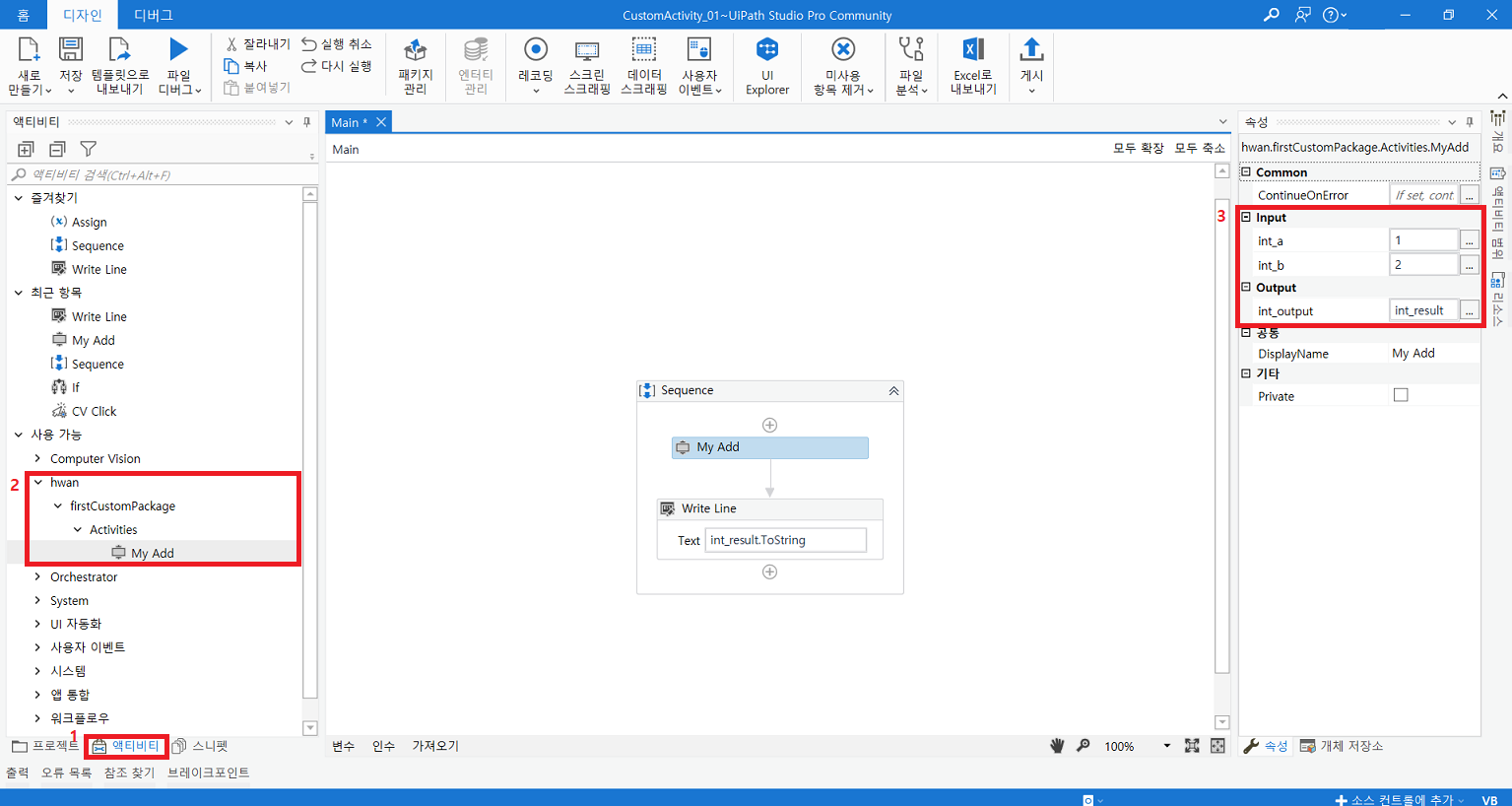
7-4) 생성된 .nupkg 파일을 특정 폴더(custom-package 배포용 폴더)에 위치시킨뒤 UiPath Stuido 에서 가져옴
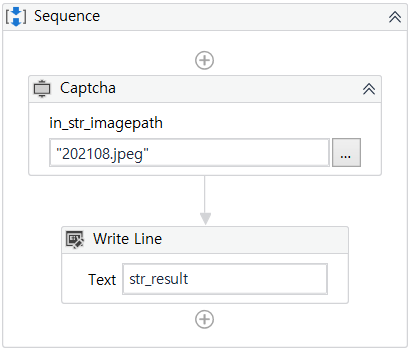
8. 결과
- 위의 6번과 같은 정확도로 결과가 도출됨

'기타 > 토이 프로젝트' 카테고리의 다른 글
| 윈도우 원격제어 프로그램 (0) | 2022.03.08 |
|---|---|
| 아두이노로 키보드 입력 방지 우회하기 (2) | 2021.09.10 |
| 미국 주식 시뮬레이터 (0) | 2021.07.25 |
| 레이싱 드론만들기 #1 재료 구매 (0) | 2021.06.09 |
| 파일 자동 분류/정리 시스템 (0) | 2017.07.11 |
| 얼굴 인식 장치 (0) | 2017.06.17 |